
Voice Issues and Requirements
![]() This section describes issues that might affect voice quality and then introduces various mechanisms that can be used to improve the quality of voice in an integrated network.
This section describes issues that might affect voice quality and then introduces various mechanisms that can be used to improve the quality of voice in an integrated network.
 Voice Quality Issues
Voice Quality Issues
![]() Overall voice quality is a function of many factors, including delay, jitter, packet loss, and echo. This section discusses these factors and ways to minimize them.
Overall voice quality is a function of many factors, including delay, jitter, packet loss, and echo. This section discusses these factors and ways to minimize them.
Packet Delays
![]() Packet delay can cause voice quality degradation. When designing networks that transport voice, you must understand and account for the network’s delay components. Correctly accounting for all potential delays ensures that overall network performance is acceptable.
Packet delay can cause voice quality degradation. When designing networks that transport voice, you must understand and account for the network’s delay components. Correctly accounting for all potential delays ensures that overall network performance is acceptable.
![]() The generally accepted limit for good quality voice connection delay is 150 milliseconds (ms) one-way. As delays increase, the communication between two people falls out of synch (for example, they speak at the same time or both wait for the other to speak); this condition is called talker overlap. The ITU describes network delay for voice applications in recommendation G.114; as shown in Table 8-3, this recommendation defines three bands of one-way delay.
The generally accepted limit for good quality voice connection delay is 150 milliseconds (ms) one-way. As delays increase, the communication between two people falls out of synch (for example, they speak at the same time or both wait for the other to speak); this condition is called talker overlap. The ITU describes network delay for voice applications in recommendation G.114; as shown in Table 8-3, this recommendation defines three bands of one-way delay.
|
| |
|---|---|
|
|
|
|
|
|
|
|
|
![]() Voice packets are delayed if the network is congested because of poor network quality, underpowered equipment, congested traffic, or insufficient bandwidth. Delay can be classified into two types: fixed network delay and variable network delay.
Voice packets are delayed if the network is congested because of poor network quality, underpowered equipment, congested traffic, or insufficient bandwidth. Delay can be classified into two types: fixed network delay and variable network delay.
Fixed Network Delays
![]() Fixed network delays result from delays in network devices and contribute directly to the overall connection delay. As shown in Figure 8-26, fixed delays have three components: propagation delay, serialization delay, and processing delay.
Fixed network delays result from delays in network devices and contribute directly to the overall connection delay. As shown in Figure 8-26, fixed delays have three components: propagation delay, serialization delay, and processing delay.


Propagation Delay
![]() Propagation delay is the length of time it takes a signal to travel the distance between the sending and receiving endpoints.
Propagation delay is the length of time it takes a signal to travel the distance between the sending and receiving endpoints.
![]() This form of delay, which is limited by the speed of light, can be ignored for most designs because it is relatively small compared to other types of delay. A popular estimate of 10 microseconds/mile or 6 microseconds/kilometer is used for estimating propagation delay.
This form of delay, which is limited by the speed of light, can be ignored for most designs because it is relatively small compared to other types of delay. A popular estimate of 10 microseconds/mile or 6 microseconds/kilometer is used for estimating propagation delay.
| Note |
|
Serialization Delay
![]() Serialization delay is the delay encountered when sending a voice or data frame onto the network interface. It is the result of placing bits on the circuit and is directly related to the circuit (link) speed.
Serialization delay is the delay encountered when sending a voice or data frame onto the network interface. It is the result of placing bits on the circuit and is directly related to the circuit (link) speed.
![]() The higher the circuit speed, the less time it takes to place the bits on the circuit and the less the serialization delay. Serialization delay is a constant function of link speed and packet size. It is calculated by the following formula:
The higher the circuit speed, the less time it takes to place the bits on the circuit and the less the serialization delay. Serialization delay is a constant function of link speed and packet size. It is calculated by the following formula:
![]() (packet length)/(bit rate)
(packet length)/(bit rate)
![]() A large serialization delay occurs with slow links or large packets. Serialization delay is always predictable; for example, when using a 64-kbps link and 80-byte frame, the delay is exactly 10 ms.
A large serialization delay occurs with slow links or large packets. Serialization delay is always predictable; for example, when using a 64-kbps link and 80-byte frame, the delay is exactly 10 ms.
| Note |
|
| Note |
|
Processing Delay
![]() Processing delays include the following:
Processing delays include the following:
- Coding, compression, decompression, and decoding delays: These delays depend on the algorithm used for these functions, which can be performed in either hardware or software. Using specialized hardware such as a DSP dramatically improves the quality and reduces the delay associated with different voice compression schemes.
- Packetization delay: This delay results from the process of holding the digital voice samples until enough are collected to fill the packet or cell payload. In some compression schemes, the voice gateway sends partial packets to reduce excessive packetization delay.
Variable Network Delays
![]() Variable network delay is more unpredictable and difficult to calculate than fixed network delay. As shown in Figure 8-27 and described in the following sections, the following three factors contribute to variable network delay: queuing delay, variable packet sizes, and dejitter buffers.
Variable network delay is more unpredictable and difficult to calculate than fixed network delay. As shown in Figure 8-27 and described in the following sections, the following three factors contribute to variable network delay: queuing delay, variable packet sizes, and dejitter buffers.


Queuing Delay and Variable Packet Sizes
![]() Queuing delay occurs when a voice packet is waiting on the outgoing interface for others to be serviced first. This waiting time is statistically based on the arrival of traffic; the more inputs, the more likely that contention is encountered for the interface. Queuing delay is also based on the size of the packet currently being serviced; larger packets take longer to transmit than do smaller packets. Therefore, a queue that combines large and small packets experiences varying lengths of delay.
Queuing delay occurs when a voice packet is waiting on the outgoing interface for others to be serviced first. This waiting time is statistically based on the arrival of traffic; the more inputs, the more likely that contention is encountered for the interface. Queuing delay is also based on the size of the packet currently being serviced; larger packets take longer to transmit than do smaller packets. Therefore, a queue that combines large and small packets experiences varying lengths of delay.
![]() Because voice should have absolute priority in the voice gateway queue, a voice frame should wait only for either a data frame that is already being sent or for other voice frames ahead of it. For example, assume that a 1500-byte data packet is queued before the voice packet. The voice packet must wait until the entire data packet is transmitted, which produces a delay in the voice path. If the link is slow (for example, 64 or 128 kbps), the queuing delay might be more than 200 ms and result in an unacceptable voice delay.
Because voice should have absolute priority in the voice gateway queue, a voice frame should wait only for either a data frame that is already being sent or for other voice frames ahead of it. For example, assume that a 1500-byte data packet is queued before the voice packet. The voice packet must wait until the entire data packet is transmitted, which produces a delay in the voice path. If the link is slow (for example, 64 or 128 kbps), the queuing delay might be more than 200 ms and result in an unacceptable voice delay.
![]() Link fragmentation and interleaving (LFI) is a solution for queuing delay situations. With LFI, the voice gateway fragments large packets into smaller equal-sized frames and interleaves them with small voice packets. Therefore, a voice packet does not have to wait until the entire large data packet is sent. LFI reduces and ensures a more predictable voice delay. Configuring LFI fragmentation on a link results in a fixed delay (for example, 10 ms); however, be sure to set the fragment size so that only data packets, not voice packets, become fragmented. Figure 8-28 illustrates the LFI concept.
Link fragmentation and interleaving (LFI) is a solution for queuing delay situations. With LFI, the voice gateway fragments large packets into smaller equal-sized frames and interleaves them with small voice packets. Therefore, a voice packet does not have to wait until the entire large data packet is sent. LFI reduces and ensures a more predictable voice delay. Configuring LFI fragmentation on a link results in a fixed delay (for example, 10 ms); however, be sure to set the fragment size so that only data packets, not voice packets, become fragmented. Figure 8-28 illustrates the LFI concept.


Dejitter Buffers
![]() Because network congestion can occur at any point in a network, interface queues can be filled instantaneously, potentially leading to a difference in delay times between packets from the same voice stream.
Because network congestion can occur at any point in a network, interface queues can be filled instantaneously, potentially leading to a difference in delay times between packets from the same voice stream.
![]() The variable delay between packets is called jitter. The next section describes jitter.
The variable delay between packets is called jitter. The next section describes jitter.
![]() Dejitter buffers are used at the receiving end to smooth delay variability and allow time for decoding and decompression.
Dejitter buffers are used at the receiving end to smooth delay variability and allow time for decoding and decompression.
| Note |
|
![]() On the first talk spurt, dejitter buffers help provide smooth playback of voice traffic. Setting these buffers too low causes overflows and data loss, whereas setting them too high causes excessive delay.
On the first talk spurt, dejitter buffers help provide smooth playback of voice traffic. Setting these buffers too low causes overflows and data loss, whereas setting them too high causes excessive delay.
![]() Dejitter buffers reduce or eliminate delay variation by converting it to a fixed delay. However, dejitter buffers always add delay; the amount depends on the variance of the delay.
Dejitter buffers reduce or eliminate delay variation by converting it to a fixed delay. However, dejitter buffers always add delay; the amount depends on the variance of the delay.
![]() Dejitter buffers work most efficiently when packets arrive with almost uniform delay. Various QoS congestion avoidance mechanisms exist to manage delay and avoid network congestion; if there is no variance in delay, dejitter buffers can be disabled, reducing the constant delay.
Dejitter buffers work most efficiently when packets arrive with almost uniform delay. Various QoS congestion avoidance mechanisms exist to manage delay and avoid network congestion; if there is no variance in delay, dejitter buffers can be disabled, reducing the constant delay.
![]() When using dejitter buffers, delay is always added to the total delay budget. Therefore, keep the dejitter buffers as small as possible to keep the delay to a minimum.
When using dejitter buffers, delay is always added to the total delay budget. Therefore, keep the dejitter buffers as small as possible to keep the delay to a minimum.
Jitter
![]() At the sending side, the originating voice gateway sends packets in a continuous stream, spaced evenly. Because of network congestion, improper queuing, or configuration errors, this steady stream can become lumpy; in other words, as shown in Figure 8-29, the delay between each packet can vary instead of remaining constant. This can be annoying to listeners.
At the sending side, the originating voice gateway sends packets in a continuous stream, spaced evenly. Because of network congestion, improper queuing, or configuration errors, this steady stream can become lumpy; in other words, as shown in Figure 8-29, the delay between each packet can vary instead of remaining constant. This can be annoying to listeners.


![]() When a voice gateway receives a VoIP audio stream, it must compensate for the jitter it encounters. The mechanism that handles this function is the dejitter buffer (as mentioned previously in the “Dejitter Buffers” section), which must buffer the packets and then play them out in a steady stream to the DSPs, which convert them back to an analog audio stream.
When a voice gateway receives a VoIP audio stream, it must compensate for the jitter it encounters. The mechanism that handles this function is the dejitter buffer (as mentioned previously in the “Dejitter Buffers” section), which must buffer the packets and then play them out in a steady stream to the DSPs, which convert them back to an analog audio stream.
Packet Loss
![]() Packet loss causes voice clipping and skips. Packet loss can occur because of congested links, improper network QoS configuration, poor packet buffer management on the routers, routing problems, and other issues in both the WAN and LAN. If queues become saturated, VoIP packets might be dropped, resulting in effects such as clicks or lost words. Losses occur if the packets are received out of range of the dejitter buffer, in which case the packets are discarded.
Packet loss causes voice clipping and skips. Packet loss can occur because of congested links, improper network QoS configuration, poor packet buffer management on the routers, routing problems, and other issues in both the WAN and LAN. If queues become saturated, VoIP packets might be dropped, resulting in effects such as clicks or lost words. Losses occur if the packets are received out of range of the dejitter buffer, in which case the packets are discarded.
![]() The industry-standard codec algorithms used in the Cisco DSP can use interpolation to correct for up to 30 ms of lost voice. The Cisco VoIP technology uses 20-ms samples of voice payload per VoIP packet. Therefore, only a single packet can be lost during any given time for the codec correction algorithms to be effective.
The industry-standard codec algorithms used in the Cisco DSP can use interpolation to correct for up to 30 ms of lost voice. The Cisco VoIP technology uses 20-ms samples of voice payload per VoIP packet. Therefore, only a single packet can be lost during any given time for the codec correction algorithms to be effective.
![]() For packet losses as small as one packet, the DSP interpolates the conversation with what it thinks the audio should be, and the packet loss is not audible.
For packet losses as small as one packet, the DSP interpolates the conversation with what it thinks the audio should be, and the packet loss is not audible.
Echo
![]() In a voice telephone call, an echo occurs when callers hear their own words repeated.
In a voice telephone call, an echo occurs when callers hear their own words repeated.
![]() Echo is a function of delay and magnitude. The echo problem grows with the delay (the later the echo is heard) and the loudness (higher amplitude). When timed properly, an echo can be reassuring to the speaker. But if the echo exceeds approximately 25 milliseconds, it can be distracting and cause breaks in the conversation.
Echo is a function of delay and magnitude. The echo problem grows with the delay (the later the echo is heard) and the loudness (higher amplitude). When timed properly, an echo can be reassuring to the speaker. But if the echo exceeds approximately 25 milliseconds, it can be distracting and cause breaks in the conversation.
![]() Perceived echo most likely indicates a problem at the other end of the call. For example, if a person in Toronto hears an echo when talking to a person in Vancouver, the problem is likely to be at the Vancouver end.
Perceived echo most likely indicates a problem at the other end of the call. For example, if a person in Toronto hears an echo when talking to a person in Vancouver, the problem is likely to be at the Vancouver end.
![]() The following voice network elements can affect echo:
The following voice network elements can affect echo:
- Hybrid transformers: A typical telephone is a two-wire device, whereas trunk connections are four-wire; a hybrid transformer is used to interface between these connections. Hybrid transformers are often prime culprits for signal leakage between analog transmit and receive paths, causing echo. Echo is usually caused by a mismatch in impedance from the four-wire network switch conversion to the two-wire local loop or an impedance mismatch in a PBX.
- Telephones: An analog telephone terminal itself presents a load to the PBX. This load should be matched to the output impedance of the source device (the FXS port). Some (typically inexpensive) telephones are not matched to the FXS port’s output impedance and are sources of echo. Headsets are particularly notorious for poor echo performance.When digital telephones are used, the point of digital-to-analog conversion occurs inside the telephone. Extending the digital transmission segments closer to the actual telephone decreases the potential for echo.
| Note |
|
![]() An echo canceller, shown in Figure 8-30, can be placed in the network to improve the quality of telephone conversation. An echo canceller is a component of a voice gateway; it reduces the level of echo leaking from the receive path into the transmit path.
An echo canceller, shown in Figure 8-30, can be placed in the network to improve the quality of telephone conversation. An echo canceller is a component of a voice gateway; it reduces the level of echo leaking from the receive path into the transmit path.
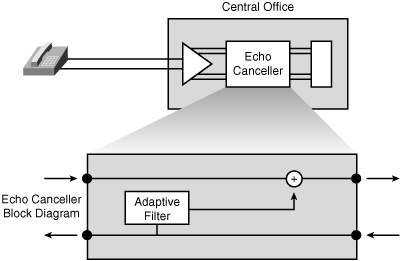
![]() Echo cancellers are built into low-bit-rate codecs and operate on each DSP. By design, echo cancellers are limited by the total amount of time they wait for the reflected speech to be received. This is known as an echo trail or echo cancellation time and is usually between 16 and 32 milliseconds.
Echo cancellers are built into low-bit-rate codecs and operate on each DSP. By design, echo cancellers are limited by the total amount of time they wait for the reflected speech to be received. This is known as an echo trail or echo cancellation time and is usually between 16 and 32 milliseconds.
![]() To understand how an echo canceller works, assume that a person in Toronto is talking to a person in Vancouver. When the speech of the person in Toronto hits an impedance mismatch or other echo-causing environment, it bounces back to that person, who can hear the echo several milliseconds after speaking.
To understand how an echo canceller works, assume that a person in Toronto is talking to a person in Vancouver. When the speech of the person in Toronto hits an impedance mismatch or other echo-causing environment, it bounces back to that person, who can hear the echo several milliseconds after speaking.
![]() Recall that the problem is at the other end of the call (called the tail circuit); in this example, the tail circuit is in Vancouver. To remove the echo from the line, the router in Toronto must keep an inverse image of the Toronto person’s speech for a certain amount of time. This is called inverse speech. The echo canceller in the router listens for sound coming from the person in Vancouver and subtracts the inverse speech of the person in Toronto to remove any echo.
Recall that the problem is at the other end of the call (called the tail circuit); in this example, the tail circuit is in Vancouver. To remove the echo from the line, the router in Toronto must keep an inverse image of the Toronto person’s speech for a certain amount of time. This is called inverse speech. The echo canceller in the router listens for sound coming from the person in Vancouver and subtracts the inverse speech of the person in Toronto to remove any echo.
![]() The ITU-T defines an irritation zone of echo loudness and echo delay. A short echo (around 15 ms) does not have to be suppressed, whereas longer echo delays require strong echo suppression. Therefore, all networks that produce one-way time delays greater than 16 ms require echo cancellation. It is important to configure the appropriate echo cancellation time. If the echo cancellation time is set too low, callers still hear echo during the phone call. If the configured echo cancellation time is set too high, it takes longer for the echo canceller to converge and eliminate the echo.
The ITU-T defines an irritation zone of echo loudness and echo delay. A short echo (around 15 ms) does not have to be suppressed, whereas longer echo delays require strong echo suppression. Therefore, all networks that produce one-way time delays greater than 16 ms require echo cancellation. It is important to configure the appropriate echo cancellation time. If the echo cancellation time is set too low, callers still hear echo during the phone call. If the configured echo cancellation time is set too high, it takes longer for the echo canceller to converge and eliminate the echo.
![]() Attenuating the signal below the noise level can also eliminate echo.
Attenuating the signal below the noise level can also eliminate echo.
Voice Coding and Compression
![]() Voice communication over IP relies on voice that is coded and encapsulated into IP packets. This section provides an overview of the various codecs used in voice networks.
Voice communication over IP relies on voice that is coded and encapsulated into IP packets. This section provides an overview of the various codecs used in voice networks.
| Note |
|
Coding and Compression Algorithms
![]() Each codec provides a certain quality of speech. Advances in technology have greatly improved the quality of compressed voice and have resulted in a variety of coding and compression algorithms:
Each codec provides a certain quality of speech. Advances in technology have greatly improved the quality of compressed voice and have resulted in a variety of coding and compression algorithms:
- PCM: The toll quality voice expected from the PSTN. PCM runs at 64 kbps and provides no compression, and therefore no opportunity for bandwidth savings.
- Adaptive Differential Pulse Code Modulation (ADPCM): Provides three different levels of compression. Some fidelity is lost as compression increases. Depending on the traffic mix, cost savings generally run at 25 percent for 32-kbps ADPCM, 30 percent for 24-kbps ADPCM, and 35 percent for 16-kbps ADPCM.
- Low-Delay Code Excited Linear Prediction Compression (LD-CELP): This algorithm models the human voice. Depending on the traffic mix, cost savings can be up to 35 percent for 16-kbps LD-CELP.
- Conjugate Structure Algebraic Code Excited Linear Prediction Compression (CS-ACELP): Provides eight times the bandwidth savings over PCM. CS-ACELP is a more recently developed algorithm modeled after the human voice and delivers quality that is comparable to LD-CELP and 32-kbps ADPCM. Cost savings are approximately 40 percent for 8-kbps CS-ACELP.
- Code Excited Linear Prediction Compression (CELP): Provides huge bandwidth savings over PCM. Cost savings can be up to 50 percent for 5.3-kbps CELP.
![]() The following section details voice coding standards based on these algorithms.
The following section details voice coding standards based on these algorithms.
Voice Coding Standards (Codecs)
![]() The ITU has defined a series of standards for voice coding and compression:
The ITU has defined a series of standards for voice coding and compression:
- G.711: Uses the 64-kbps PCM voice coding technique. G.711-encoded voice is already in the correct format for digital voice delivery in the PSTN or through PBXs. Most Cisco implementations use G.711 on LAN links because of its high quality, approaching toll quality.
- G.726/G.727: G.726 uses the ADPCM coding at 40, 32, 24, and 16 kbps. ADPCM voice can be interchanged between packet voice and public telephone or PBX networks if the latter has ADPCM capability. G.727 is a specialized version of G.726; it includes the same bandwidths.
- G.728: Uses the LD-CELP voice compression, which requires only 16 kbps of bandwidth. LD-CELP voice coding must be transcoded to a PCM-based coding before delivering to the PSTN.
- G.729: Uses the CS-ACELP compression, which enables voice to be coded into 8-kbps streams. This standard has various forms, all of which provide speech quality similar to that of 32-kbps ADPCM.For example, in G.729a, the basic algorithm was optimized to reduce the computation requirements. In G.729b, voice activity detection (VAD) and comfort noise generation were added. G.729ab provides an optimized version of G.729b requiring less computation.
- G.723.1: Uses a dual-rate coder for compressing speech at very low bit rates. Two bit rates are associated with this standard: 5.3 kbps using algebraic code-excited linear prediction (ACELP) and 6.3 kbps using Multipulse Maximum Likelihood Quantization (MPMLQ).
Sound Quality
![]() Each codec provides a certain quality of speech. The perceived quality of transmitted speech depends on a listener’s subjective response.
Each codec provides a certain quality of speech. The perceived quality of transmitted speech depends on a listener’s subjective response.
![]() The mean opinion score (MOS) is a common benchmark used to specify the quality of sound produced by specific codecs. To determine the MOS, a wide range of listeners judge the quality of a voice sample corresponding to a particular codec on a scale of 1 (bad) to 5 (excellent). The scores are averaged to provide the MOS for that sample. Table 8-4 shows the relationship between codecs and MOS scores; notice that MOS decreases with increased codec complexity.
The mean opinion score (MOS) is a common benchmark used to specify the quality of sound produced by specific codecs. To determine the MOS, a wide range of listeners judge the quality of a voice sample corresponding to a particular codec on a scale of 1 (bad) to 5 (excellent). The scores are averaged to provide the MOS for that sample. Table 8-4 shows the relationship between codecs and MOS scores; notice that MOS decreases with increased codec complexity.
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]() G.729 is the recommended voice codec for most WAN networks (that do not do multiple encodings) because of its relatively low bandwidth requirements and high MOS.
G.729 is the recommended voice codec for most WAN networks (that do not do multiple encodings) because of its relatively low bandwidth requirements and high MOS.
![]() The Perceptual Speech Quality Measurement (PSQM) is a newer, more objective measurement that is overtaking MOS scores as the industry quality measurement of choice for coding algorithms. PSQM is specified in ITU standard P.861. PSQM provides a rating on a scale of 0 to 6.5, where 0 is best and 6.5 is worst. PSQM is implemented in test equipment and monitoring systems. It compares the transmitted speech to the original input to produce a PSQM score for a test voice call over a particular packet network. Some PSQM test equipment converts the 0-to-6.5 scale to a 0-to-5 scale to correlate to MOS.
The Perceptual Speech Quality Measurement (PSQM) is a newer, more objective measurement that is overtaking MOS scores as the industry quality measurement of choice for coding algorithms. PSQM is specified in ITU standard P.861. PSQM provides a rating on a scale of 0 to 6.5, where 0 is best and 6.5 is worst. PSQM is implemented in test equipment and monitoring systems. It compares the transmitted speech to the original input to produce a PSQM score for a test voice call over a particular packet network. Some PSQM test equipment converts the 0-to-6.5 scale to a 0-to-5 scale to correlate to MOS.
Codec Complexity, DSPs, and Voice Calls
![]() A DSP is a hardware component that converts information from telephony-based protocols to packet-based protocols (such as IP).
A DSP is a hardware component that converts information from telephony-based protocols to packet-based protocols (such as IP).
![]() A codec is a technology for compressing and decompressing data; it is implemented in DSPs. Some codec compression techniques require more processing power than others.
A codec is a technology for compressing and decompressing data; it is implemented in DSPs. Some codec compression techniques require more processing power than others.
![]() Codec complexity is divided into low, medium, and high complexity. The difference between the complexities of the codecs is the CPU utilization necessary to process the codec algorithm and the number of voice channels that a single DSP can support.
Codec complexity is divided into low, medium, and high complexity. The difference between the complexities of the codecs is the CPU utilization necessary to process the codec algorithm and the number of voice channels that a single DSP can support.
![]() The number of calls supported depends on the DSP and the complexity of the codec used. For example, as illustrated in Table 8-5, the Cisco High-Density Packet Voice/Fax DSP Module (AS54-PVDM2-64) for Cisco voice gateways provides high-density voice connectivity supporting 24 to 64 channels (calls), depending on codec compression complexity.
The number of calls supported depends on the DSP and the complexity of the codec used. For example, as illustrated in Table 8-5, the Cisco High-Density Packet Voice/Fax DSP Module (AS54-PVDM2-64) for Cisco voice gateways provides high-density voice connectivity supporting 24 to 64 channels (calls), depending on codec compression complexity.
|
|
|
|
|---|---|---|
|
|
|
|
Bandwidth Considerations
![]() Bandwidth availability is a key issue to consider when designing voice on IP networks. The amount of bandwidth per call varies greatly, depending on which codec is used and how many voice samples are required per packet. However, the best coding mechanism does not necessarily result in the best voice quality; for example, the better the compression, the worse the voice quality. The designer must decide which is more important: better voice quality or more efficient bandwidth consumption.
Bandwidth availability is a key issue to consider when designing voice on IP networks. The amount of bandwidth per call varies greatly, depending on which codec is used and how many voice samples are required per packet. However, the best coding mechanism does not necessarily result in the best voice quality; for example, the better the compression, the worse the voice quality. The designer must decide which is more important: better voice quality or more efficient bandwidth consumption.
Reducing the Amount of Voice Traffic
![]() Two techniques reduce the amount of traffic per voice call and therefore use available bandwidth more efficiently: cRTP and VAD.
Two techniques reduce the amount of traffic per voice call and therefore use available bandwidth more efficiently: cRTP and VAD.
Compressed Real-Time Transport Protocol
![]() All voice packets encapsulated into IP consist of two components: the payload, which is the voice sample, and IP/UDP/RTP headers. Although voice samples are compressed by the DSP and can vary in size based on the codec used, the headers are a constant 40 bytes. When compared to the 20 bytes of voice samples in a G.729 call, the headers make up a considerable amount of overhead. As illustrated in Figure 8-31, cRTP compresses the headers to 2 or 4 bytes, thereby offering significant bandwidth savings. cRTP is sometimes referred to as RTP header compression. RFC 2508, Compressing IP/UDP/RTP Headers for Low-Speed Serial Links, describes cRTP.
All voice packets encapsulated into IP consist of two components: the payload, which is the voice sample, and IP/UDP/RTP headers. Although voice samples are compressed by the DSP and can vary in size based on the codec used, the headers are a constant 40 bytes. When compared to the 20 bytes of voice samples in a G.729 call, the headers make up a considerable amount of overhead. As illustrated in Figure 8-31, cRTP compresses the headers to 2 or 4 bytes, thereby offering significant bandwidth savings. cRTP is sometimes referred to as RTP header compression. RFC 2508, Compressing IP/UDP/RTP Headers for Low-Speed Serial Links, describes cRTP.


![]() Enabling compression on a low-bandwidth serial link can greatly reduce the network overhead and conserve WAN bandwidth if there is a significant volume of RTP traffic. In general, enable cRTP on slow links up to 768 kbps. However, cRTP is not recommended for higher-speed links because of its high CPU requirements.
Enabling compression on a low-bandwidth serial link can greatly reduce the network overhead and conserve WAN bandwidth if there is a significant volume of RTP traffic. In general, enable cRTP on slow links up to 768 kbps. However, cRTP is not recommended for higher-speed links because of its high CPU requirements.
| Note |
|
Voice Activity Detection
![]() On average, about 35 percent of calls are silence. In traditional voice networks, all voice calls use a fixed bandwidth of 64 kbps regardless of how much of the conversation is speech and how much is silence. When VoIP is used, this silence is packetized along with the conversation. VAD suppresses packets of silence, so instead of sending IP packets of silence, only IP packets of conversation are sent. Therefore, gateways can interleave data traffic with actual voice conversation traffic, resulting in more effective use of the network bandwidth.
On average, about 35 percent of calls are silence. In traditional voice networks, all voice calls use a fixed bandwidth of 64 kbps regardless of how much of the conversation is speech and how much is silence. When VoIP is used, this silence is packetized along with the conversation. VAD suppresses packets of silence, so instead of sending IP packets of silence, only IP packets of conversation are sent. Therefore, gateways can interleave data traffic with actual voice conversation traffic, resulting in more effective use of the network bandwidth.
| Note |
|
Voice Bandwidth Requirements
![]() When building voice networks, one of the most important factors to consider is bandwidth capacity planning. One of the most critical concepts to understand within capacity planning is how much bandwidth is used for each VoIP call.
When building voice networks, one of the most important factors to consider is bandwidth capacity planning. One of the most critical concepts to understand within capacity planning is how much bandwidth is used for each VoIP call.
![]() Table 8-6 presents a selection of codec payload sizes and the required bandwidth without compression and with cRTP. The last column shows the number of uncompressed and compressed calls that can be made on a 512-kbps link.
Table 8-6 presents a selection of codec payload sizes and the required bandwidth without compression and with cRTP. The last column shows the number of uncompressed and compressed calls that can be made on a 512-kbps link.
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]() The following assumptions are made in Table 8-6’s bandwidth calculations:
The following assumptions are made in Table 8-6’s bandwidth calculations:
- IP/UDP/RTP headers are 40 bytes.
- RTP header compression can reduce the IP/UDP/RTP headers to 2 or 4 bytes. Table 8-6 uses 2 bytes.
- A Layer 2 header adds 6 bytes.
![]() Table 8-6 uses the following calculations:
Table 8-6 uses the following calculations:
- Voice packet size = (Layer 2 header) + (IP/UDP/RTP header) + (voice payload)
- Voice packets per second (pps) = codec bit rate/voice payload size
- Bandwidth per call = voice packet size * voice pps
![]() For example, the following steps illustrate how to calculate the bandwidth required for a G.729 call (8-kbps codec bit rate) with cRTP and default 20 bytes of voice payload:
For example, the following steps illustrate how to calculate the bandwidth required for a G.729 call (8-kbps codec bit rate) with cRTP and default 20 bytes of voice payload:
- Voice packet size (bytes) = (Layer 2 header of 6 bytes) + (compressed IP/UDP/RTP header of 2 bytes) + (voice payload of 20 bytes) = 28 bytes
- Voice packet size (bits) = (28 bytes) * 8 bits per byte = 224 bits
- Voice packets per second = (8-kbps codec bit rate)/(8 bits/byte * 20 bytes) = (8-kbps codec bit rate)/(160 bits) = 50 pps
- Bandwidth per call = voice packet size (224 bits) * 50 pps = 11.2 kbps
![]() Result: The G.729 call with cRTP requires 11.2 kbps of bandwidth. This value is rounded down to 11 in Table 8-6.
Result: The G.729 call with cRTP requires 11.2 kbps of bandwidth. This value is rounded down to 11 in Table 8-6.
![]() A more precise estimate of voice codec bandwidth can be obtained using the Cisco Voice Codec Bandwidth Calculator available at http://tools.cisco.com/Support/VBC/do/CodecCalc1.do.
A more precise estimate of voice codec bandwidth can be obtained using the Cisco Voice Codec Bandwidth Calculator available at http://tools.cisco.com/Support/VBC/do/CodecCalc1.do.
| Note |
|
![]() Figure 8-32 shows a portion of the results of the Cisco Voice Codec Bandwidth Calculator for the G.729 codec. This calculation uses cRTP and includes 5 percent additional overhead to accommodate the bandwidth required for signaling.
Figure 8-32 shows a portion of the results of the Cisco Voice Codec Bandwidth Calculator for the G.729 codec. This calculation uses cRTP and includes 5 percent additional overhead to accommodate the bandwidth required for signaling.


Codec Design Considerations
![]() Although it might seem logical from a bandwidth consumption standpoint to convert all calls to low-bit-rate codecs to save bandwidth and consequently decrease infrastructure costs, the designer should consider both the expected voice quality and the bandwidth consumption when choosing the optimum codec. The designer should also consider the disadvantages of strong voice compression, including signal distortion resulting from multiple encodings. For example, when a G.729 voice signal is tandem-encoded three times, the MOS score drops from 3.92 (very good) to 2.68 (unacceptable). Another drawback is the codec-induced delay with low-bit-rate codecs.
Although it might seem logical from a bandwidth consumption standpoint to convert all calls to low-bit-rate codecs to save bandwidth and consequently decrease infrastructure costs, the designer should consider both the expected voice quality and the bandwidth consumption when choosing the optimum codec. The designer should also consider the disadvantages of strong voice compression, including signal distortion resulting from multiple encodings. For example, when a G.729 voice signal is tandem-encoded three times, the MOS score drops from 3.92 (very good) to 2.68 (unacceptable). Another drawback is the codec-induced delay with low-bit-rate codecs.
QoS for Voice
![]() IP telephony places strict requirements on IP packet loss, packet delay, and delay variation (jitter). Therefore, QoS mechanisms on Cisco switches and routers are important throughout the network if voice traffic is sharing network resources with data traffic. Redundant devices and network links that provide quick convergence after network failures or topology changes are also important to ensure a highly available infrastructure. The following summarizes the process to determine whether to implement QoS in a network:
IP telephony places strict requirements on IP packet loss, packet delay, and delay variation (jitter). Therefore, QoS mechanisms on Cisco switches and routers are important throughout the network if voice traffic is sharing network resources with data traffic. Redundant devices and network links that provide quick convergence after network failures or topology changes are also important to ensure a highly available infrastructure. The following summarizes the process to determine whether to implement QoS in a network:
![]() Figure 8-33 identifies some of the QoS mechanisms available, many of which were introduced in Chapter 4, “Designing Basic Campus and Data Center Networks,” and Chapter 5. The specifics of these mechanisms for voice are reviewed here, followed by a discussion of Call Admission Control (CAC). QoS practices in the Building Access Layer are also described. This section concludes with a discussion of AutoQoS.
Figure 8-33 identifies some of the QoS mechanisms available, many of which were introduced in Chapter 4, “Designing Basic Campus and Data Center Networks,” and Chapter 5. The specifics of these mechanisms for voice are reviewed here, followed by a discussion of Call Admission Control (CAC). QoS practices in the Building Access Layer are also described. This section concludes with a discussion of AutoQoS.


Bandwidth Provisioning
![]() Bandwidth provisioning involves accurately calculating the required bandwidth for all applications, plus the required overhead. CAC should be used to avoid using more bandwidth than has been provisioned.
Bandwidth provisioning involves accurately calculating the required bandwidth for all applications, plus the required overhead. CAC should be used to avoid using more bandwidth than has been provisioned.
Signaling Techniques
![]() The Resource Reservation Protocol (RSVP) allows bandwidth and other resources along the routing path to be reserved so that a certain level of quality is provided for delay-sensitive traffic. Other signaling techniques include Frame Relay’s Forward Explicit Congestion Notification and Backward Explicit Congestion Notification, and those used with the various ATM adaptation types.
The Resource Reservation Protocol (RSVP) allows bandwidth and other resources along the routing path to be reserved so that a certain level of quality is provided for delay-sensitive traffic. Other signaling techniques include Frame Relay’s Forward Explicit Congestion Notification and Backward Explicit Congestion Notification, and those used with the various ATM adaptation types.
Classification and Marking
![]() Packet classification is the process of partitioning traffic into multiple priority levels or classes of service. Information in the frame or packet header is inspected, and the frame’s priority is determined. Marking is the process of changing the priority or class of service (CoS) setting within a frame or packet to indicate its classification.
Packet classification is the process of partitioning traffic into multiple priority levels or classes of service. Information in the frame or packet header is inspected, and the frame’s priority is determined. Marking is the process of changing the priority or class of service (CoS) setting within a frame or packet to indicate its classification.
![]() Classification is usually performed with access control lists (ACL), QoS class maps, or route maps, using various match criteria. Network-based application recognition, described in Chapter 2, “Applying a Methodology to Network Design,” can also be used for classification. Matches can be based on the following criteria:
Classification is usually performed with access control lists (ACL), QoS class maps, or route maps, using various match criteria. Network-based application recognition, described in Chapter 2, “Applying a Methodology to Network Design,” can also be used for classification. Matches can be based on the following criteria:
- Protocol, such as a stateful protocol or a Layer 4 protocol
- Input port
- IP precedence or differentiated services code point (DSCP)
- Ethernet IEEE 802.1p CoS bits
![]() Marking is done at Layer 3 or Layer 2:
Marking is done at Layer 3 or Layer 2:
- Layer 3 marking changes the IP precedence bits or DSCP values in the IP packet to reflect the result of QoS classification.
- For IEEE 802.1Q frames, the 3 user priority bits in the Tag field—commonly referred to as the 802.1p bits—are used as CoS bits for Layer 2 marking; eight classes of traffic are possible with these 3 bits. Cisco IP phones, for example, can classify and mark VoIP traffic using the 802.1p bits.
Congestion Avoidance
![]() Recall from Chapter 5 that congestion-avoidance techniques monitor network traffic loads so that congestion can be anticipated and avoided before it becomes problematic. Congestion-avoidance techniques allow packets from streams identified as being eligible for early discard (those with lower priority) to be dropped when the queue is getting full. Congestion-avoidance techniques provide preferential treatment for high priority traffic under congestion situations while maximizing network throughput and capacity utilization and minimizing packet loss and delay.
Recall from Chapter 5 that congestion-avoidance techniques monitor network traffic loads so that congestion can be anticipated and avoided before it becomes problematic. Congestion-avoidance techniques allow packets from streams identified as being eligible for early discard (those with lower priority) to be dropped when the queue is getting full. Congestion-avoidance techniques provide preferential treatment for high priority traffic under congestion situations while maximizing network throughput and capacity utilization and minimizing packet loss and delay.
![]() Weighted random early detection (WRED) is the Cisco implementation of the random early detection (RED) mechanism. WRED extends RED by using the IP Precedence bits in the IP packet header to determine which traffic should be dropped; the drop-selection process is weighted by the IP precedence. Similarly, DSCP-based WRED uses the DSCP value in the IP packet header in the drop-selection process. Distributed WRED (DWRED) is an implementation of WRED for the Versatile Interface Processor (VIP). The DWRED feature is supported only on Cisco 7000 series routers with a Route Switch Processor–based RSP7000 interface processor and Cisco 7500 series routers with a VIP-based VIP2-40 or greater interface processor.
Weighted random early detection (WRED) is the Cisco implementation of the random early detection (RED) mechanism. WRED extends RED by using the IP Precedence bits in the IP packet header to determine which traffic should be dropped; the drop-selection process is weighted by the IP precedence. Similarly, DSCP-based WRED uses the DSCP value in the IP packet header in the drop-selection process. Distributed WRED (DWRED) is an implementation of WRED for the Versatile Interface Processor (VIP). The DWRED feature is supported only on Cisco 7000 series routers with a Route Switch Processor–based RSP7000 interface processor and Cisco 7500 series routers with a VIP-based VIP2-40 or greater interface processor.
Traffic Policing and Shaping
![]() Traffic shaping and traffic policing, also referred to as committed access rate (CAR), are similar mechanisms in that they both inspect traffic and take action based on the various characteristics of that traffic. These characteristics can be based on whether the traffic is over or under a given rate or based on some bits in the IP packet header, such as the DSCP or IP Precedence bits.
Traffic shaping and traffic policing, also referred to as committed access rate (CAR), are similar mechanisms in that they both inspect traffic and take action based on the various characteristics of that traffic. These characteristics can be based on whether the traffic is over or under a given rate or based on some bits in the IP packet header, such as the DSCP or IP Precedence bits.
![]() Policing either discards the packet or modifies some aspect of it, such as its IP Precedence or CoS bits, when the policing agent determines that the packet meets a given criterion. In comparison, traffic shaping attempts to adjust the transmission rate of packets that match a certain criterion. A shaper typically delays excess traffic by using a buffer or queuing mechanism to hold packets and shape the flow when the source’s data rate is higher than expected. For example, generic traffic shaping uses a weighted fair queue to delay packets to shape the flow, whereas Frame Relay traffic shaping uses a priority queue, a custom queue, or a FIFO queue, depending on how it is configured.
Policing either discards the packet or modifies some aspect of it, such as its IP Precedence or CoS bits, when the policing agent determines that the packet meets a given criterion. In comparison, traffic shaping attempts to adjust the transmission rate of packets that match a certain criterion. A shaper typically delays excess traffic by using a buffer or queuing mechanism to hold packets and shape the flow when the source’s data rate is higher than expected. For example, generic traffic shaping uses a weighted fair queue to delay packets to shape the flow, whereas Frame Relay traffic shaping uses a priority queue, a custom queue, or a FIFO queue, depending on how it is configured.
Congestion Management: Queuing and Scheduling
![]() As noted in Chapter 5, congestion management includes two separate processes: queuing, which separates traffic into various queues or buffers, and scheduling, which decides from which queue traffic is to be sent next.
As noted in Chapter 5, congestion management includes two separate processes: queuing, which separates traffic into various queues or buffers, and scheduling, which decides from which queue traffic is to be sent next.
![]() Queuing is configured on outbound interfaces and is appropriate for cases in which WAN links are occasionally congested.
Queuing is configured on outbound interfaces and is appropriate for cases in which WAN links are occasionally congested.
![]() There are two types of queues: the hardware queue (also called the transmit queue or TxQ) and software queues. Software queues schedule packets into the hardware queue based on the QoS requirements and include the following types: weighted fair queuing (WFQ), priority queuing (PQ), custom queuing (CQ), class-based WFQ (CBWFQ), and low latency queuing (LLQ).
There are two types of queues: the hardware queue (also called the transmit queue or TxQ) and software queues. Software queues schedule packets into the hardware queue based on the QoS requirements and include the following types: weighted fair queuing (WFQ), priority queuing (PQ), custom queuing (CQ), class-based WFQ (CBWFQ), and low latency queuing (LLQ).
![]() LLQ adds strict priority queuing to CBWFQ; LLQ is a combination of CBWFQ and PQ. Strict priority queuing allows delay-sensitive data, such as voice, to be dequeued and sent first (before packets in other queues are dequeued), thereby giving the delay-sensitive traffic preferential treatment over other traffic.
LLQ adds strict priority queuing to CBWFQ; LLQ is a combination of CBWFQ and PQ. Strict priority queuing allows delay-sensitive data, such as voice, to be dequeued and sent first (before packets in other queues are dequeued), thereby giving the delay-sensitive traffic preferential treatment over other traffic.
![]() LLQ is the recommended queuing mechanism for voice on IP networks. The voice traffic should be put in the priority queue.
LLQ is the recommended queuing mechanism for voice on IP networks. The voice traffic should be put in the priority queue.
![]() Figure 8-34 illustrates why LLQ is the preferred queuing mechanism for voice transport on integrated networks. The LLQ policing mechanism guarantees bandwidth for voice and gives it priority over other traffic, which is queued based on CBWFQ. LLQ reduces jitter in voice conversations.
Figure 8-34 illustrates why LLQ is the preferred queuing mechanism for voice transport on integrated networks. The LLQ policing mechanism guarantees bandwidth for voice and gives it priority over other traffic, which is queued based on CBWFQ. LLQ reduces jitter in voice conversations.

Link Efficiency
![]() Link efficiency techniques, including LFI and compression, can be applied to WAN paths. Recall that LFI prevents small voice packets from being queued behind large data packets, which could lead to unacceptable delays on low-speed links. With LFI, the voice gateway fragments large packets into smaller equal-sized frames and interleaves them with small voice packets so that a voice packet does not have to wait until the entire large data packet is sent. LFI reduces and ensures a more predictable voice delay.
Link efficiency techniques, including LFI and compression, can be applied to WAN paths. Recall that LFI prevents small voice packets from being queued behind large data packets, which could lead to unacceptable delays on low-speed links. With LFI, the voice gateway fragments large packets into smaller equal-sized frames and interleaves them with small voice packets so that a voice packet does not have to wait until the entire large data packet is sent. LFI reduces and ensures a more predictable voice delay.
![]() Compression of voice packets includes both header compression and payload compression. cRTP is used to compress large IP/UDP/RTP headers. The various codecs described in the earlier “Voice Coding and Compression” section compress the payload (the voice).
Compression of voice packets includes both header compression and payload compression. cRTP is used to compress large IP/UDP/RTP headers. The various codecs described in the earlier “Voice Coding and Compression” section compress the payload (the voice).
CAC
![]() CAC mechanisms extend the QoS capabilities to protect voice traffic from being negatively affected by other voice traffic by keeping excess voice traffic off the network. The CAC function should be performed during the call setup phase so that if no network resources are available, a message can be sent to the end user, or the call can be rerouted across a different network, such as the PSTN.
CAC mechanisms extend the QoS capabilities to protect voice traffic from being negatively affected by other voice traffic by keeping excess voice traffic off the network. The CAC function should be performed during the call setup phase so that if no network resources are available, a message can be sent to the end user, or the call can be rerouted across a different network, such as the PSTN.
![]() CAC is an essential component of any IP telephony system that includes multiple sites connected through an IP WAN. If the provisioned voice bandwidth in the WAN is fully utilized, subsequent calls must be rejected to avoid oversubscribing the WAN, which would cause the quality of all voice calls to degrade. This function is provided by CAC to guarantee good voice quality in a multisite deployment involving an IP WAN.
CAC is an essential component of any IP telephony system that includes multiple sites connected through an IP WAN. If the provisioned voice bandwidth in the WAN is fully utilized, subsequent calls must be rejected to avoid oversubscribing the WAN, which would cause the quality of all voice calls to degrade. This function is provided by CAC to guarantee good voice quality in a multisite deployment involving an IP WAN.
Location-Based CAC
![]() The location feature in Cisco Unified Communications Manager lets you specify the maximum bandwidth available for calls to and from each location, thereby limiting the number of active calls and preventing the WAN from being oversubscribed.
The location feature in Cisco Unified Communications Manager lets you specify the maximum bandwidth available for calls to and from each location, thereby limiting the number of active calls and preventing the WAN from being oversubscribed.
![]() For example, if a WAN link between two PBXs has only enough bandwidth to carry two VoIP calls, admitting a third call impairs the voice quality of all three calls. The queuing mechanisms that provide policing cause this problem; if packets that exceed the configured or allowable rate are received, they are tail-dropped from the queue. The queuing mechanism cannot distinguish which IP packet belongs to which voice call; any packets that exceed the given arrival rate within a certain period are dropped. As a result, all three calls experience packet loss, and end users perceive clipped speech.
For example, if a WAN link between two PBXs has only enough bandwidth to carry two VoIP calls, admitting a third call impairs the voice quality of all three calls. The queuing mechanisms that provide policing cause this problem; if packets that exceed the configured or allowable rate are received, they are tail-dropped from the queue. The queuing mechanism cannot distinguish which IP packet belongs to which voice call; any packets that exceed the given arrival rate within a certain period are dropped. As a result, all three calls experience packet loss, and end users perceive clipped speech.
![]() When CAC is implemented, the outgoing voice gateway detects that insufficient network resources are available for a call to proceed. The call is rejected, and the originating gateway must find another means of handling the call. In the absence of any specific configuration, the outgoing gateway provides the calling party with a reorder tone, which might cause the PSTN switch or PBX to announce that “All circuits are busy; please try your call again later.” The outgoing voice gateway can be configured for the following scenarios:
When CAC is implemented, the outgoing voice gateway detects that insufficient network resources are available for a call to proceed. The call is rejected, and the originating gateway must find another means of handling the call. In the absence of any specific configuration, the outgoing gateway provides the calling party with a reorder tone, which might cause the PSTN switch or PBX to announce that “All circuits are busy; please try your call again later.” The outgoing voice gateway can be configured for the following scenarios:
- The call can be rerouted via an alternative packet network path, if such a path exists.
- The call can be rerouted via the PSTN network path.
- The call can be returned to the originating TDM switch with the reject cause code.
![]() Figure 8-35 shows examples of a VoIP network with and without CAC.
Figure 8-35 shows examples of a VoIP network with and without CAC.


![]() The upper diagram in Figure 8-35 illustrates a VoIP network without CAC. The WAN link between the two PBXs has the bandwidth to carry only two VoIP calls. In this example, admitting the third call impairs the voice quality of all three calls.
The upper diagram in Figure 8-35 illustrates a VoIP network without CAC. The WAN link between the two PBXs has the bandwidth to carry only two VoIP calls. In this example, admitting the third call impairs the voice quality of all three calls.
![]() The lower example in Figure 8-35 illustrates a VoIP network with CAC. If the outgoing gateway detects that insufficient network resources are available to allow a call to proceed, the gateway automatically reroutes the third call to the PSTN, thereby maintaining the voice quality of the two existing calls.
The lower example in Figure 8-35 illustrates a VoIP network with CAC. If the outgoing gateway detects that insufficient network resources are available to allow a call to proceed, the gateway automatically reroutes the third call to the PSTN, thereby maintaining the voice quality of the two existing calls.
CAC with RSVP
![]() CAC can be also be implemented with RSVP. Cisco Unified Communications Manager Version 5.0 supports the Cisco RSVP Agent, which enables more efficient use of networks. The Cisco RSVP Agent provides an additional method to achieve CAC besides location-based CAC. RSVP can handle more complex topologies than location-based CAC, which supports only hub-and-spoke network topologies.
CAC can be also be implemented with RSVP. Cisco Unified Communications Manager Version 5.0 supports the Cisco RSVP Agent, which enables more efficient use of networks. The Cisco RSVP Agent provides an additional method to achieve CAC besides location-based CAC. RSVP can handle more complex topologies than location-based CAC, which supports only hub-and-spoke network topologies.
![]() RSVP is an industry-standard signaling protocol that enables an application to reserve bandwidth dynamically across an IP network. RSVP, which runs over IP, was first introduced by the IETF in RFC 2205, Resource ReSerVation Protocol (RSVP)—Version 1 Functional Specification. Using RSVP, applications request a certain amount of bandwidth for a data flow across a network (for example, a voice call) and receive an indication of the outcome of the reservation based on actual resource availability. RSVP defines signaling messages that are exchanged between the source and destination devices for the data flow and that are processed by intermediate routers along the path. The RSVP signaling messages are encapsulated in IP packets that are routed through the network according to the existing routing protocols.
RSVP is an industry-standard signaling protocol that enables an application to reserve bandwidth dynamically across an IP network. RSVP, which runs over IP, was first introduced by the IETF in RFC 2205, Resource ReSerVation Protocol (RSVP)—Version 1 Functional Specification. Using RSVP, applications request a certain amount of bandwidth for a data flow across a network (for example, a voice call) and receive an indication of the outcome of the reservation based on actual resource availability. RSVP defines signaling messages that are exchanged between the source and destination devices for the data flow and that are processed by intermediate routers along the path. The RSVP signaling messages are encapsulated in IP packets that are routed through the network according to the existing routing protocols.
![]() Not all routers on the path are required to support RSVP; the protocol is designed to operate transparently across RSVP-unaware nodes. On each RSVP-enabled router, the RSVP process intercepts the signaling messages and interacts with the QoS manager for the router interfaces involved in the data flow to “reserve” bandwidth resources. If the available resources anywhere along the path are not sufficient for the data flow, the routers send a signal indicating the failure to the application that originated the reservation request.
Not all routers on the path are required to support RSVP; the protocol is designed to operate transparently across RSVP-unaware nodes. On each RSVP-enabled router, the RSVP process intercepts the signaling messages and interacts with the QoS manager for the router interfaces involved in the data flow to “reserve” bandwidth resources. If the available resources anywhere along the path are not sufficient for the data flow, the routers send a signal indicating the failure to the application that originated the reservation request.
![]() For example, a branch office router has a primary link with an LLQ provisioned for ten calls and a backup link that can accommodate two calls. RSVP can be configured on both router interfaces so that the RSVP bandwidth matches the LLQ bandwidth. The call processing agent at the branch can be configured to require RSVP reservations for all calls to or from other branches. Calls are admitted or rejected based on the outcome of the RSVP reservations, which automatically follow the path determined by the routing protocol. Under normal conditions (when the primary link is active), up to ten calls will be admitted; during failure of the primary link, only up to two calls will be admitted.
For example, a branch office router has a primary link with an LLQ provisioned for ten calls and a backup link that can accommodate two calls. RSVP can be configured on both router interfaces so that the RSVP bandwidth matches the LLQ bandwidth. The call processing agent at the branch can be configured to require RSVP reservations for all calls to or from other branches. Calls are admitted or rejected based on the outcome of the RSVP reservations, which automatically follow the path determined by the routing protocol. Under normal conditions (when the primary link is active), up to ten calls will be admitted; during failure of the primary link, only up to two calls will be admitted.
![]() Policies can typically be set within the call processing agent to determine what to do in the case of a CAC failure. For example, the call could be rejected, rerouted across the PSTN, or sent across the IP WAN as a best-effort call with a different DSCP marking.
Policies can typically be set within the call processing agent to determine what to do in the case of a CAC failure. For example, the call could be rejected, rerouted across the PSTN, or sent across the IP WAN as a best-effort call with a different DSCP marking.
Building Access Layer QoS Mechanisms for Voice
![]() To provide high-quality voice and to take advantage of the full voice feature set, QoS mechanisms on Building Access layer switches include the following:
To provide high-quality voice and to take advantage of the full voice feature set, QoS mechanisms on Building Access layer switches include the following:
- On 802.1Q trunks, the three 802.1p user priority bits in the Tag field are used as the CoS bits. Layer 2 CoS marking is performed on Layer 2 ports to which IP phones are connected.
- Multiple egress queues provide priority queuing of RTP voice packet streams.
- The ability to classify or reclassify traffic and establish a trust boundary. A trust boundary is the point within the network where markings are accepted; any markings made by devices outside the trust boundary can be overwritten at the trust boundary.Establishing a trust boundary means that the classification and marking processes can be done once, at the boundary; the rest of the network does not have to repeat the analysis. Ideally, the trust boundary is as close to end devices as possible—or even within the end devices. For example, a Cisco IP phone could be considered a trusted device because it marks voice traffic appropriately. However, a user’s PC would not usually be trusted because users could change markings, which they might be tempted to do in an attempt to increase the priority of their traffic.
- Layer 3 awareness and the ability to implement QoS ACLs might be required if certain IP telephony endpoints are used, such as a PC running a software-based IP phone application that cannot benefit from an extended trust boundary.
![]() These mechanisms protect voice from packet loss and delay stemming from oversubscription of aggregate links between switches, which might cause egress interface buffers to become full instantaneously. When voice packets are subject to drops, delay, and jitter, the user-perceivable effects include a clicking sound, harsh-sounding voice, extended periods of silence, and echo.
These mechanisms protect voice from packet loss and delay stemming from oversubscription of aggregate links between switches, which might cause egress interface buffers to become full instantaneously. When voice packets are subject to drops, delay, and jitter, the user-perceivable effects include a clicking sound, harsh-sounding voice, extended periods of silence, and echo.
![]() When deploying voice, it is recommended that two VLANs be enabled in the Building Access Layer switch: a native VLAN for data traffic and a voice VLAN for voice traffic. Note that a voice VLAN in the Cisco IOS software is called an auxiliary VLAN under the Catalyst operating system. Separate voice and data VLANs are recommended for the following reasons:
When deploying voice, it is recommended that two VLANs be enabled in the Building Access Layer switch: a native VLAN for data traffic and a voice VLAN for voice traffic. Note that a voice VLAN in the Cisco IOS software is called an auxiliary VLAN under the Catalyst operating system. Separate voice and data VLANs are recommended for the following reasons:
- Configuring RFC 1918 private addressing on phones on the voice (or auxiliary) VLAN conserves addresses and ensures that phones are not accessible directly via public networks. PCs and servers can be addressed with public addresses; however, voice endpoints should be addressed using private addresses.
- QoS trust boundaries can be selectively extended to voice devices without extending the trust boundaries to PCs and other data devices.
- VLAN access control and 802.1p tagging provide protection for voice devices from malicious internal and external network attacks such as worms, denial-of-service attacks, and attempts by data devices to gain access to priority queues via packet tagging.
- Management and QoS configuration are simplified.
| Note |
|
AutoQoS
![]() The Cisco AutoQoS feature on routers and switches provides a simple, automatic way to enable QoS configurations in conformance with Cisco’s best-practice recommendations. Only one command is required; the router or switch then creates configuration commands to perform such things as classifying and marking VoIP traffic and then applying an LLQ queuing strategy on WAN links for that traffic. The configuration created by AutoQoS becomes part of the normal configuration file and therefore can be edited if required. The first phase of AutoQoS, available in various versions of the router Cisco IOS Release 12.3, creates only configurations related to VoIP traffic.
The Cisco AutoQoS feature on routers and switches provides a simple, automatic way to enable QoS configurations in conformance with Cisco’s best-practice recommendations. Only one command is required; the router or switch then creates configuration commands to perform such things as classifying and marking VoIP traffic and then applying an LLQ queuing strategy on WAN links for that traffic. The configuration created by AutoQoS becomes part of the normal configuration file and therefore can be edited if required. The first phase of AutoQoS, available in various versions of the router Cisco IOS Release 12.3, creates only configurations related to VoIP traffic.
| Note |
|
![]() The second phase of AutoQoS is called AutoQoS Enterprise and includes support for all types of data. It configures the router with commands to classify, mark, and handle packets in up to 10 of the 11 QoS Baseline traffic classes (as described in Chapter 5). The Mission-Critical traffic class is the only one not defined, because it is specific to each organization. As with the earlier release, the commands created by AutoQoS Enterprise can be edited if required.
The second phase of AutoQoS is called AutoQoS Enterprise and includes support for all types of data. It configures the router with commands to classify, mark, and handle packets in up to 10 of the 11 QoS Baseline traffic classes (as described in Chapter 5). The Mission-Critical traffic class is the only one not defined, because it is specific to each organization. As with the earlier release, the commands created by AutoQoS Enterprise can be edited if required.
| Note |
|
0 comments
Post a Comment