
WAN Design
![]() This section describes the WAN design methodology and the application and technical requirement aspects of WAN design. The different possibilities for WAN ownership are discussed. WAN bandwidth optimization techniques are described.
This section describes the WAN design methodology and the application and technical requirement aspects of WAN design. The different possibilities for WAN ownership are discussed. WAN bandwidth optimization techniques are described.
![]() The methodology espoused here follows the guidelines of the Prepare-Plan-Design-Implement-Operate-Optimize (PPDIOO) methodology introduced in Chapter 2, “Applying a Methodology to Network Design.” The network designer should follow these steps when planning and designing the Enterprise Edge based on the PPDIOO methodology:
The methodology espoused here follows the guidelines of the Prepare-Plan-Design-Implement-Operate-Optimize (PPDIOO) methodology introduced in Chapter 2, “Applying a Methodology to Network Design.” The network designer should follow these steps when planning and designing the Enterprise Edge based on the PPDIOO methodology:
|
|
|
|
|
|
|
|
|
![]() Planning and designing WAN networks involves a number of trade-offs, including the following:
Planning and designing WAN networks involves a number of trade-offs, including the following:
-
 Application aspects of the requirements driven by the performance analysis
Application aspects of the requirements driven by the performance analysis - Technical aspects of the requirements dealing with the geographic regulations and the effectiveness of the selected technology
- Cost aspects of the requirements; costs include those of the equipment and of the owned or leased media or communication channel
| Note |
|
![]() The network’s design should also be adaptable for the inclusion of future technologies and should not include any design elements that limit the adoption of new technologies as they become available. There might be trade-offs between these considerations and cost throughout the network design and implementation. For example, many new internetworks are rapidly adopting VoIP technology. Network designs should be able to support this technology without requiring a substantial upgrade by provisioning hardware and software that have options for expansion and upgradeability.
The network’s design should also be adaptable for the inclusion of future technologies and should not include any design elements that limit the adoption of new technologies as they become available. There might be trade-offs between these considerations and cost throughout the network design and implementation. For example, many new internetworks are rapidly adopting VoIP technology. Network designs should be able to support this technology without requiring a substantial upgrade by provisioning hardware and software that have options for expansion and upgradeability.
Application Requirements of WAN Design
![]() Just as application requirements drive the Enterprise Campus design (as illustrated in Chapter 4, “Designing Basic Campus and Data Center Networks”), they also affect the Enterprise Edge WAN design. Application availability is a key user requirement; the chief components of application availability are response time, throughput, packet loss, and reliability. Table 5-2 analyzes these components, which are discussed in the following sections.
Just as application requirements drive the Enterprise Campus design (as illustrated in Chapter 4, “Designing Basic Campus and Data Center Networks”), they also affect the Enterprise Edge WAN design. Application availability is a key user requirement; the chief components of application availability are response time, throughput, packet loss, and reliability. Table 5-2 analyzes these components, which are discussed in the following sections.
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||||
Response Time
![]() Response time is the time between a user request (such as the entry of a command or keystroke) and the host system’s command execution or response delivery.
Response time is the time between a user request (such as the entry of a command or keystroke) and the host system’s command execution or response delivery.
![]() Users accept response times up to some limit, at which point user satisfaction declines. Applications for which fast response time is considered critical include interactive online services, such as point-of-sale machines.
Users accept response times up to some limit, at which point user satisfaction declines. Applications for which fast response time is considered critical include interactive online services, such as point-of-sale machines.
| Note |
|
Throughput
![]() In data transmission, throughput is the amount of data moved successfully from one place to another in a given time period.
In data transmission, throughput is the amount of data moved successfully from one place to another in a given time period.
![]() Applications that put high-volume traffic onto the network have more effect on throughput than interactive end-to-end connections. Throughput-intensive applications typically involve file-transfer activities that usually have low response-time requirements and can often be scheduled at times when response-time-sensitive traffic is low (such as after normal work hours). This could be accomplished via time-based access lists, for example.
Applications that put high-volume traffic onto the network have more effect on throughput than interactive end-to-end connections. Throughput-intensive applications typically involve file-transfer activities that usually have low response-time requirements and can often be scheduled at times when response-time-sensitive traffic is low (such as after normal work hours). This could be accomplished via time-based access lists, for example.
Packet Loss
![]() In telecommunication transmission, packet loss is expressed as a bit error rate (BER), which is the percentage of bits that have errors, relative to the total number of bits received in a transmission.
In telecommunication transmission, packet loss is expressed as a bit error rate (BER), which is the percentage of bits that have errors, relative to the total number of bits received in a transmission.
![]() BER is usually expressed as 10 to a negative power. For example, a transmission might have a BER of 10 to the minus 6 (10-6), meaning that 1 bit out of 1,000,000 bits transmitted was in error. The BER indicates how frequently a packet or other data unit must be retransmitted because of an error. A BER that is too high might indicate that a slower data rate could improve the overall transmission time for a given amount of transmitted data; in other words, a slower data rate can reduce the BER, thereby lowering the number of packets that must be re-sent.
BER is usually expressed as 10 to a negative power. For example, a transmission might have a BER of 10 to the minus 6 (10-6), meaning that 1 bit out of 1,000,000 bits transmitted was in error. The BER indicates how frequently a packet or other data unit must be retransmitted because of an error. A BER that is too high might indicate that a slower data rate could improve the overall transmission time for a given amount of transmitted data; in other words, a slower data rate can reduce the BER, thereby lowering the number of packets that must be re-sent.
Reliability
![]() Although reliability is always important, some applications have requirements that exceed typical needs. Financial services, securities exchanges, and emergency, police, and military operations are examples of organizations that require nearly 100 percent uptime for critical applications. These situations imply a requirement for a high level of hardware and topological redundancy. Determining the cost of any downtime is essential for determining the relative importance of the network’s reliability.
Although reliability is always important, some applications have requirements that exceed typical needs. Financial services, securities exchanges, and emergency, police, and military operations are examples of organizations that require nearly 100 percent uptime for critical applications. These situations imply a requirement for a high level of hardware and topological redundancy. Determining the cost of any downtime is essential for determining the relative importance of the network’s reliability.
Technical Requirements: Maximum Offered Traffic
![]() The goal of every WAN design should be to optimize link performance in terms of offered traffic, link utilization, and response time. To optimize link performance, the designer must balance between end-user and network manager requirements, which are usually diametrically opposed. End users usually require minimum application response times over a WAN link, whereas the network manager’s goal is to maximize the link utilization; WAN resources have finite capacity.
The goal of every WAN design should be to optimize link performance in terms of offered traffic, link utilization, and response time. To optimize link performance, the designer must balance between end-user and network manager requirements, which are usually diametrically opposed. End users usually require minimum application response times over a WAN link, whereas the network manager’s goal is to maximize the link utilization; WAN resources have finite capacity.
![]() Response time problems typically affect only users. For example, it probably does not matter to the network manager if query results are returned 120 ms sooner rather than later. Response time is a thermometer of usability for users. Users perceive the data processing experience in terms of how quickly they can get their screen to update. They view the data processing world in terms of response time and do not usually care about link utilization. The graphs in Figure 5-11 illustrate the response time and link utilization relative to the offered traffic. The response time increases with the offered traffic, until it reaches an unacceptable point for the end user. Similarly, the link utilization increases with the offered traffic to the point that the link becomes saturated. The designer’s goal is to determine the maximum offered traffic that is acceptable to both the end user and the network manager.
Response time problems typically affect only users. For example, it probably does not matter to the network manager if query results are returned 120 ms sooner rather than later. Response time is a thermometer of usability for users. Users perceive the data processing experience in terms of how quickly they can get their screen to update. They view the data processing world in terms of response time and do not usually care about link utilization. The graphs in Figure 5-11 illustrate the response time and link utilization relative to the offered traffic. The response time increases with the offered traffic, until it reaches an unacceptable point for the end user. Similarly, the link utilization increases with the offered traffic to the point that the link becomes saturated. The designer’s goal is to determine the maximum offered traffic that is acceptable to both the end user and the network manager.


![]() However, planning for additional WAN capacity should occur much earlier than the critical point—usually at about 50% link utilization. Additional bandwidth purchasing should start at about 60% utilization; if the link utilization reaches 75%, increasing the capacity is critical.
However, planning for additional WAN capacity should occur much earlier than the critical point—usually at about 50% link utilization. Additional bandwidth purchasing should start at about 60% utilization; if the link utilization reaches 75%, increasing the capacity is critical.
Technical Requirements: Bandwidth
![]() In a qualitative sense, the required bandwidth is proportional to the data’s complexity for a given level of system performance. For example, downloading a photograph in 1 second takes more bandwidth than downloading a page of text in 1 second. Large sound files, computer programs, and animated videos require even more bandwidth for acceptable system performance. One of the main issues involved in WAN connections is the selection of appropriate technologies that provide sufficient bandwidth. Table 5-3 illustrates the ranges of bandwidths commonly supported by the given technologies.
In a qualitative sense, the required bandwidth is proportional to the data’s complexity for a given level of system performance. For example, downloading a photograph in 1 second takes more bandwidth than downloading a page of text in 1 second. Large sound files, computer programs, and animated videos require even more bandwidth for acceptable system performance. One of the main issues involved in WAN connections is the selection of appropriate technologies that provide sufficient bandwidth. Table 5-3 illustrates the ranges of bandwidths commonly supported by the given technologies.
|
| ||||
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
| ||
|
|
|
|
| |
|
|
| |||
|
|
| |||
![]() Bandwidth is inexpensive in the LAN, where connectivity is typically limited only by hardware, implementation, and ongoing maintenance costs. In the WAN, bandwidth has typically been the overriding cost, and delay-sensitive traffic such as voice has remained separate from data. However, new applications and the economics of supporting them are forcing these conventions to change.
Bandwidth is inexpensive in the LAN, where connectivity is typically limited only by hardware, implementation, and ongoing maintenance costs. In the WAN, bandwidth has typically been the overriding cost, and delay-sensitive traffic such as voice has remained separate from data. However, new applications and the economics of supporting them are forcing these conventions to change.
Evaluating the Cost-Effectiveness of WAN Ownership
![]() In the WAN environment, the following usually represent fixed costs:
In the WAN environment, the following usually represent fixed costs:
- Equipment purchases, such as modems, channel service unit/data service units, and router interfaces
- Circuit and service provisioning
- Network-management tools and platforms
![]() Recurring costs include the monthly circuit fees from the SP and the WAN’s support and maintenance, including any network management center personnel.
Recurring costs include the monthly circuit fees from the SP and the WAN’s support and maintenance, including any network management center personnel.
![]() From an ownership perspective, WAN links can be thought of in the following three categories:
From an ownership perspective, WAN links can be thought of in the following three categories:
- Private: A private WAN uses private transmission systems to connect distant LANs. The owner of a private WAN must buy, configure, and maintain the physical layer connectivity (such as copper, fiber, wireless, and coaxial) and the terminal equipment required to connect locations. This makes private WANs expensive to build, labor-intensive to maintain, and difficult to reconfigure for constantly changing business needs. The advantages of using a private WAN might include higher levels of security and transmission quality.
Note When the WAN media and devices are privately owned, transmission quality is not necessarily improved, nor is reliability necessarily higher. - Leased: A leased WAN uses dedicated bandwidth from a carrier company, with either private or leased terminal equipment. The provider provisions the circuit and provides the maintenance. However, the company pays for the allocated bandwidth whether or not it is used, and operating costs tend to be high. Some examples include TDM and SONET circuits.
- Shared: A shared WAN shares the physical resources with many users. Carriers offer a variety of circuit- or packet-switching transport networks, such as MPLS and Frame Relay. The provider provisions the circuit and provides the maintenance. Linking LANs and private WANs into shared network services is a trade-off among cost, performance, and security. An ideal design optimizes the cost advantages of shared network services with a company’s performance and security requirements.
| Note |
|
Optimizing Bandwidth in a WAN
![]() It is expensive to transmit data over a WAN. Therefore, one of many different techniques—such as data compression, bandwidth combination, tuning window size, congestion management (queuing and scheduling), congestion avoidance, and traffic shaping and policing—can be used to optimize bandwidth usage and improve overall performance. The following sections describe these techniques.
It is expensive to transmit data over a WAN. Therefore, one of many different techniques—such as data compression, bandwidth combination, tuning window size, congestion management (queuing and scheduling), congestion avoidance, and traffic shaping and policing—can be used to optimize bandwidth usage and improve overall performance. The following sections describe these techniques.
Data Compression
![]() Compression enables more efficient use of the available WAN bandwidth, which is often limited and is generally a bottleneck. Compression allows higher throughput because it squeezes packet size and therefore increases the amount of data that can be sent through a transmission resource in a given time period. Compression can be of an entire packet, of the header only, or of the payload only. Payload compression is performed on a Layer 2 frame’s payload and therefore compresses the entire Layer 3 packet.
Compression enables more efficient use of the available WAN bandwidth, which is often limited and is generally a bottleneck. Compression allows higher throughput because it squeezes packet size and therefore increases the amount of data that can be sent through a transmission resource in a given time period. Compression can be of an entire packet, of the header only, or of the payload only. Payload compression is performed on a Layer 2 frame’s payload and therefore compresses the entire Layer 3 packet.
![]() You can easily measure the success of these solutions using compression ratio and platform latency. However, although compression might seem like a viable WAN bandwidth optimization feature, it might not always be appropriate. Cisco IOS software compression support includes the following data software compression types:
You can easily measure the success of these solutions using compression ratio and platform latency. However, although compression might seem like a viable WAN bandwidth optimization feature, it might not always be appropriate. Cisco IOS software compression support includes the following data software compression types:
- FRF.9 Frame Relay Payload Compression
- Link Access Procedure Balanced payload compression using the Lempel-Ziv Stack (LZS) algorithm, which is commonly referred to as the Stacker (STAC) or Predictor algorithm
- HDLC using LZS
- X.25 payload compression of encapsulated traffic
- PPP using Predictor
- Van Jacobson header compression for TCP/IP (conforms to RFC 1144)
- Microsoft Point-to-Point Compression
![]() The basic function of data compression is to reduce the size of a frame of data to be transmitted over a network link. Data compression algorithms use two types of encoding techniques, statistical and dictionary:
The basic function of data compression is to reduce the size of a frame of data to be transmitted over a network link. Data compression algorithms use two types of encoding techniques, statistical and dictionary:
- Statistical compression, which uses a fixed, usually nonadaptive encoding method, is best applied to a single application where the data is relatively consistent and predictable. Because the traffic on internetworks is neither consistent nor predictable, statistical algorithms are usually not suitable for data compression implementations on routers.
- An example of dictionary compression is the Lempel-Ziv algorithm, which is based on a dynamically encoded dictionary that replaces a continuous stream of characters with codes. The symbols represented by the codes are stored in memory in a dictionary-style list. This approach is more responsive to variations in data than statistical compression.
![]() Cisco internetworking devices use the Stacker (abbreviated as STAC) and Predictor data compression algorithms. Developed by STAC Electronics, STAC is based on the Lempel-Ziv algorithm. The Cisco IOS software uses an optimized version of STAC that provides good compression ratios but requires many CPU cycles to perform compression.
Cisco internetworking devices use the Stacker (abbreviated as STAC) and Predictor data compression algorithms. Developed by STAC Electronics, STAC is based on the Lempel-Ziv algorithm. The Cisco IOS software uses an optimized version of STAC that provides good compression ratios but requires many CPU cycles to perform compression.
![]() The Predictor compression algorithm tries to predict the next sequence of characters in the data stream by using an index to look up a sequence in the compression dictionary. It then examines the next sequence in the data stream to see whether it matches. If so, that sequence replaces the looked-up sequence in the dictionary. If not, the algorithm locates the next character sequence in the index, and the process begins again. The index updates itself by hashing a few of the most recent character sequences from the input stream.
The Predictor compression algorithm tries to predict the next sequence of characters in the data stream by using an index to look up a sequence in the compression dictionary. It then examines the next sequence in the data stream to see whether it matches. If so, that sequence replaces the looked-up sequence in the dictionary. If not, the algorithm locates the next character sequence in the index, and the process begins again. The index updates itself by hashing a few of the most recent character sequences from the input stream.
![]() The Predictor data compression algorithm was obtained from the public domain and optimized by Cisco engineers. It uses CPU cycles more efficiently than STAC does, but it also requires more memory.
The Predictor data compression algorithm was obtained from the public domain and optimized by Cisco engineers. It uses CPU cycles more efficiently than STAC does, but it also requires more memory.
![]() Real-Time Transport Protocol (RTP) is used for carrying packetized audio and video traffic over an IP network. RTP is not intended for data traffic, which uses TCP or User Datagram Protocol. RTP provides end-to-end network transport functions intended for applications that have real-time transmission requirements such as audio, video, or simulation data over multicast or unicast network services. Because RTP header compression (cRTP) compresses the voice headers from 40 bytes to 2 or 4 bytes, it offers significant bandwidth savings. cRTP is also referred to as Compressed Real-Time Transfer Protocol.
Real-Time Transport Protocol (RTP) is used for carrying packetized audio and video traffic over an IP network. RTP is not intended for data traffic, which uses TCP or User Datagram Protocol. RTP provides end-to-end network transport functions intended for applications that have real-time transmission requirements such as audio, video, or simulation data over multicast or unicast network services. Because RTP header compression (cRTP) compresses the voice headers from 40 bytes to 2 or 4 bytes, it offers significant bandwidth savings. cRTP is also referred to as Compressed Real-Time Transfer Protocol.
![]() Hardware-assisted data compression achieves the same goal as software-based data compression, except that it accelerates compression rates by offloading the task from the main CPU to specialized compression circuits. Compression is implemented in compression hardware that is installed in a system slot.
Hardware-assisted data compression achieves the same goal as software-based data compression, except that it accelerates compression rates by offloading the task from the main CPU to specialized compression circuits. Compression is implemented in compression hardware that is installed in a system slot.
![]() System performance can be affected when compression or encryption is performed in software rather than hardware. Perform the following operations to determine whether these services are stressing a router’s CPU:
System performance can be affected when compression or encryption is performed in software rather than hardware. Perform the following operations to determine whether these services are stressing a router’s CPU:
- Use the show processes Cisco IOS software command to obtain a baseline reading before enabling encryption or compression.
- Enable the service, and use the show processes command again to assess the difference.
![]() Cisco recommends that you disable compression or encryption if the router CPU load exceeds 40 percent, and that you disable compression if encryption is enabled. Also, do not enable compression on your routers if the files being sent across the network are already compressed (such as zip files).
Cisco recommends that you disable compression or encryption if the router CPU load exceeds 40 percent, and that you disable compression if encryption is enabled. Also, do not enable compression on your routers if the files being sent across the network are already compressed (such as zip files).
Bandwidth Combination
![]() PPP is commonly used to establish a direct connection between two devices; PPP is a Layer 2 protocol for connection over synchronous and asynchronous circuits. For example, PPP is used when connecting computers using serial cables, phone lines, trunk lines, cellular telephones, specialized radio links, or fiber-optic links. As mentioned earlier, ISPs use PPP for customer dial-up access to the Internet. An encapsulated form of PPP (PPPoE or PPPoA) is commonly used in a similar role with DSL Internet service.
PPP is commonly used to establish a direct connection between two devices; PPP is a Layer 2 protocol for connection over synchronous and asynchronous circuits. For example, PPP is used when connecting computers using serial cables, phone lines, trunk lines, cellular telephones, specialized radio links, or fiber-optic links. As mentioned earlier, ISPs use PPP for customer dial-up access to the Internet. An encapsulated form of PPP (PPPoE or PPPoA) is commonly used in a similar role with DSL Internet service.
![]() Multilink PPP (MLP) logically connects multiple links between two systems, as needed, to provide extra bandwidth. The bandwidths of two or more physical communication links, such as analog modems, ISDN, and other analog or digital links, are logically aggregated, resulting in an increase in overall throughput. MLP is based on the IETF standard RFC 1990, The PPP Multilink Protocol (MP).
Multilink PPP (MLP) logically connects multiple links between two systems, as needed, to provide extra bandwidth. The bandwidths of two or more physical communication links, such as analog modems, ISDN, and other analog or digital links, are logically aggregated, resulting in an increase in overall throughput. MLP is based on the IETF standard RFC 1990, The PPP Multilink Protocol (MP).
Window Size
![]() Window size is the maximum number of frames (or amount of data) the sender can transmit before it must wait for an acknowledgment. The current window is defined as the number of frames (or amount of data) that can be sent at the current time; this is always less than or equal to the window size.
Window size is the maximum number of frames (or amount of data) the sender can transmit before it must wait for an acknowledgment. The current window is defined as the number of frames (or amount of data) that can be sent at the current time; this is always less than or equal to the window size.
![]() Window size is an important tuning factor for achieving high throughput on a WAN link. The acknowledgment procedure confirms the correct delivery of the data to the recipient. Acknowledgment procedures can be implemented at any protocol layer. They are particularly important in a protocol layer that provides reliability, such as hop-by-hop acknowledgment in a reliable link protocol or end-to-end acknowledgment in a transport protocol (for example, TCP). This form of data acknowledgment provides a means of self-clocking the network, such that a steady-state flow of data between the connection’s two endpoints is possible.
Window size is an important tuning factor for achieving high throughput on a WAN link. The acknowledgment procedure confirms the correct delivery of the data to the recipient. Acknowledgment procedures can be implemented at any protocol layer. They are particularly important in a protocol layer that provides reliability, such as hop-by-hop acknowledgment in a reliable link protocol or end-to-end acknowledgment in a transport protocol (for example, TCP). This form of data acknowledgment provides a means of self-clocking the network, such that a steady-state flow of data between the connection’s two endpoints is possible.
![]() For example, if the TCP window size is set to 8192 octets, the sender must stop after sending 8192 octets in the event that the receiver does not send an acknowledgment. This might be unacceptable for long (high-latency) WAN links with significant delays, in which the transmitter would waste the majority of its time waiting. The more acknowledgments (because of a smaller window size) and the longer the distance, the lower the throughput. Therefore, on highly reliable WAN links that do not require many acknowledgments, the window size should be adjusted to a higher value to enable maximum throughput. However, the risk is frequent retransmissions in the case of poor-quality links, which can dramatically reduce the throughput. Adjustable windows and equipment that can adapt to line conditions are strongly recommended.
For example, if the TCP window size is set to 8192 octets, the sender must stop after sending 8192 octets in the event that the receiver does not send an acknowledgment. This might be unacceptable for long (high-latency) WAN links with significant delays, in which the transmitter would waste the majority of its time waiting. The more acknowledgments (because of a smaller window size) and the longer the distance, the lower the throughput. Therefore, on highly reliable WAN links that do not require many acknowledgments, the window size should be adjusted to a higher value to enable maximum throughput. However, the risk is frequent retransmissions in the case of poor-quality links, which can dramatically reduce the throughput. Adjustable windows and equipment that can adapt to line conditions are strongly recommended.
![]() The TCP selective acknowledgment mechanism, which is defined in RFC 2018, TCP Selective Acknowledgment Options, helps overcome the limitations of the TCP acknowledgments. TCP performance can be affected if multiple packets are lost from one window of data; a TCP sender learns about only one lost packet per round trip. With selective acknowledgment enabled (using the ip tcp selective-ack global configuration command in Cisco IOS), the receiver returns selective acknowledgment packets to the sender, informing the sender about data that has been received. The sender can then resend only the missing data segments.
The TCP selective acknowledgment mechanism, which is defined in RFC 2018, TCP Selective Acknowledgment Options, helps overcome the limitations of the TCP acknowledgments. TCP performance can be affected if multiple packets are lost from one window of data; a TCP sender learns about only one lost packet per round trip. With selective acknowledgment enabled (using the ip tcp selective-ack global configuration command in Cisco IOS), the receiver returns selective acknowledgment packets to the sender, informing the sender about data that has been received. The sender can then resend only the missing data segments.
![]() This feature is used only when multiple packets drop from a TCP window. Performance is not affected when the feature is enabled but not used.
This feature is used only when multiple packets drop from a TCP window. Performance is not affected when the feature is enabled but not used.
Queuing to Improve Link Utilization
![]() To improve link utilization, Cisco has developed QoS techniques to avoid temporary congestion and to provide preferential treatment for critical applications. QoS mechanisms such as queuing and scheduling, policing (limiting) the access rate, and traffic shaping enable network operators to deploy and operate large-scale networks that efficiently handle both bandwidth-hungry (such as multimedia and web traffic) and mission-critical applications (such as host-based applications).
To improve link utilization, Cisco has developed QoS techniques to avoid temporary congestion and to provide preferential treatment for critical applications. QoS mechanisms such as queuing and scheduling, policing (limiting) the access rate, and traffic shaping enable network operators to deploy and operate large-scale networks that efficiently handle both bandwidth-hungry (such as multimedia and web traffic) and mission-critical applications (such as host-based applications).
![]() QoS does not create bandwidth; rather, QoS optimizes the use of existing resources, including bandwidth.
QoS does not create bandwidth; rather, QoS optimizes the use of existing resources, including bandwidth.
![]() If WAN links are constantly congested, either the network requires greater bandwidth or compression should be used.
If WAN links are constantly congested, either the network requires greater bandwidth or compression should be used.
![]() QoS queuing strategies are unnecessary if WAN links are never congested.
QoS queuing strategies are unnecessary if WAN links are never congested.
![]() Congestion management includes two separate processes: queuing, which separates traffic into various queues or buffers, and scheduling, which decides from which queue traffic is to be sent next.
Congestion management includes two separate processes: queuing, which separates traffic into various queues or buffers, and scheduling, which decides from which queue traffic is to be sent next.
![]() Queuing allows network administrators to manage the varying demands of applications on networks and routers. When positioning the role of queuing in networks, the primary issue is the duration of congestion.
Queuing allows network administrators to manage the varying demands of applications on networks and routers. When positioning the role of queuing in networks, the primary issue is the duration of congestion.
![]() Queuing is configured on outbound interfaces and is appropriate for cases in which WAN links are congested from time to time.
Queuing is configured on outbound interfaces and is appropriate for cases in which WAN links are congested from time to time.
![]() Following are the two types of queues:
Following are the two types of queues:
- Hardware queue: Uses a FIFO strategy, which is necessary for the interface drivers to transmit packets one by one. The hardware queue is sometimes referred to as the transmit queue or TxQ.
- Software queue: Schedules packets into the hardware queue based on the QoS requirements. The following sections discuss the following types of queuing: weighted fair queuing (WFQ), priority queuing (PQ), custom queuing (CQ), class-based WFQ (CBWFQ), and low-latency queuing (LLQ).
WFQ
![]() WFQ handles the problems inherent in queuing schemes on a FIFO basis. WFQ assesses the size of each message and ensures that high-volume senders do not force low-volume senders out of the queue. WFQ sorts different traffic flows into separate streams, or conversation sessions, and alternately dispatches them. The algorithm also solves the problem of round-trip delay variability. When high-volume conversations are active, their transfer rates and interarrival periods are quite predictable.
WFQ handles the problems inherent in queuing schemes on a FIFO basis. WFQ assesses the size of each message and ensures that high-volume senders do not force low-volume senders out of the queue. WFQ sorts different traffic flows into separate streams, or conversation sessions, and alternately dispatches them. The algorithm also solves the problem of round-trip delay variability. When high-volume conversations are active, their transfer rates and interarrival periods are quite predictable.
![]() WFQ is enabled by default on most low-speed serial interfaces (with speeds at or below 2.048 Mbps) on Cisco routers. (Faster links use a FIFO queue by default.) This makes it very easy to configure (there are few adjustable parameters) but does not allow much control over which traffic takes priority.
WFQ is enabled by default on most low-speed serial interfaces (with speeds at or below 2.048 Mbps) on Cisco routers. (Faster links use a FIFO queue by default.) This makes it very easy to configure (there are few adjustable parameters) but does not allow much control over which traffic takes priority.
PQ
![]() PQ is useful for time-sensitive, mission-critical protocols (such as IBM Systems Network Architecture traffic). PQ works by establishing four interface output queues (high, medium, normal, and low), each serving a different level of priority; queues are configurable for queue type, traffic assignment, and size. The dispatching algorithm begins servicing a queue only when all higher-priority queues are empty. This way, PQ ensures that the most important traffic placed in the higher-level queues gets through first, at the expense of all other traffic types. As shown in Figure 5-12, the high-priority queue is always emptied before the lower-priority queues are serviced. Traffic can be assigned to the various queues based on protocol, port number, or other criteria. Because priority queuing requires extra processing, you should not recommend it unless it is necessary.
PQ is useful for time-sensitive, mission-critical protocols (such as IBM Systems Network Architecture traffic). PQ works by establishing four interface output queues (high, medium, normal, and low), each serving a different level of priority; queues are configurable for queue type, traffic assignment, and size. The dispatching algorithm begins servicing a queue only when all higher-priority queues are empty. This way, PQ ensures that the most important traffic placed in the higher-level queues gets through first, at the expense of all other traffic types. As shown in Figure 5-12, the high-priority queue is always emptied before the lower-priority queues are serviced. Traffic can be assigned to the various queues based on protocol, port number, or other criteria. Because priority queuing requires extra processing, you should not recommend it unless it is necessary.


CQ
![]() CQ is a different approach for prioritizing traffic. Like PQ, traffic can be assigned to various queues based on protocol, port number, or other criteria. However, CQ handles the queues in a round-robin fashion.
CQ is a different approach for prioritizing traffic. Like PQ, traffic can be assigned to various queues based on protocol, port number, or other criteria. However, CQ handles the queues in a round-robin fashion.
![]() CQ works by establishing up to 16 interface output queues that are configurable in terms of type, traffic assignment, and size. CQ specifies the transmission window size of each queue in bytes. When the appropriate number of frames is transmitted from a queue, the transmission window size is reached, and the next queue is checked. CQ is a less drastic solution for mission-critical applications than PQ because it guarantees some level of service to all traffic.
CQ works by establishing up to 16 interface output queues that are configurable in terms of type, traffic assignment, and size. CQ specifies the transmission window size of each queue in bytes. When the appropriate number of frames is transmitted from a queue, the transmission window size is reached, and the next queue is checked. CQ is a less drastic solution for mission-critical applications than PQ because it guarantees some level of service to all traffic.
![]() CQ is fairer than PQ, but PQ is more powerful for prioritizing a mission-critical protocol. For example, with CQ, you can prioritize a particular protocol by assigning it more queue space; however, it will never monopolize the bandwidth. Figure 5-13 illustrates the custom queuing process.
CQ is fairer than PQ, but PQ is more powerful for prioritizing a mission-critical protocol. For example, with CQ, you can prioritize a particular protocol by assigning it more queue space; however, it will never monopolize the bandwidth. Figure 5-13 illustrates the custom queuing process.

![]() Like PQ, CQ causes the router to perform extra processing. Do not recommend CQ unless you have determined that one or more protocols need special processing.
Like PQ, CQ causes the router to perform extra processing. Do not recommend CQ unless you have determined that one or more protocols need special processing.
CBWFQ
![]() CBWFQ allows you to define a traffic class and then assign characteristics to it. For example, you can designate the minimum bandwidth delivered to the class during congestion. CBWFQ extends the standard WFQ functionality to provide support for user-defined traffic classes. With CBWFQ, traffic classes are defined based on match criteria, including protocols, access control lists (ACL), and input interfaces. Packets that satisfy the match criteria for a class constitute the traffic for that class. A queue is reserved for each class, and traffic that belongs to a class is directed to the queue for that class.
CBWFQ allows you to define a traffic class and then assign characteristics to it. For example, you can designate the minimum bandwidth delivered to the class during congestion. CBWFQ extends the standard WFQ functionality to provide support for user-defined traffic classes. With CBWFQ, traffic classes are defined based on match criteria, including protocols, access control lists (ACL), and input interfaces. Packets that satisfy the match criteria for a class constitute the traffic for that class. A queue is reserved for each class, and traffic that belongs to a class is directed to the queue for that class.
![]() After a class has been defined according to its match criteria, you can assign it characteristics, including bandwidth, weight, and maximum queue packet limit. The bandwidth assigned to a class is the guaranteed bandwidth delivered to the class during times of congestion.
After a class has been defined according to its match criteria, you can assign it characteristics, including bandwidth, weight, and maximum queue packet limit. The bandwidth assigned to a class is the guaranteed bandwidth delivered to the class during times of congestion.
![]() The queue packet limit is the maximum number of packets allowed to accumulate in the queue for the class. Packets that belong to a class are subject to the bandwidth and queue limits that characterize the class.
The queue packet limit is the maximum number of packets allowed to accumulate in the queue for the class. Packets that belong to a class are subject to the bandwidth and queue limits that characterize the class.
![]() For CBWFQ, the weight for a packet that belongs to a specific class derives from the bandwidth assigned to the class during configuration. Therefore, the bandwidth assigned to the packets of a class determines the order in which packets are sent. All packets are serviced fairly, based on weight; no class of packets may be granted strict priority. This scheme poses problems for voice traffic, which is largely intolerant of delay and variation in delay.
For CBWFQ, the weight for a packet that belongs to a specific class derives from the bandwidth assigned to the class during configuration. Therefore, the bandwidth assigned to the packets of a class determines the order in which packets are sent. All packets are serviced fairly, based on weight; no class of packets may be granted strict priority. This scheme poses problems for voice traffic, which is largely intolerant of delay and variation in delay.
LLQ
![]() LLQ brings strict PQ to CBWFQ; it is a combination of PQ and CBWFQ. Strict PQ allows delay-sensitive data such as voice to be dequeued and sent first (before packets in other queues are dequeued), giving delay-sensitive data preferential treatment over other traffic. Without LLQ, CBWFQ provides WFQ based on defined classes with no strict priority queue available for real-time traffic.
LLQ brings strict PQ to CBWFQ; it is a combination of PQ and CBWFQ. Strict PQ allows delay-sensitive data such as voice to be dequeued and sent first (before packets in other queues are dequeued), giving delay-sensitive data preferential treatment over other traffic. Without LLQ, CBWFQ provides WFQ based on defined classes with no strict priority queue available for real-time traffic.
Congestion Avoidance
![]() Congestion-avoidance techniques monitor network traffic loads so that congestion can be anticipated and avoided before it becomes problematic. If congestion-avoidance techniques are not used and interface queues become full, packets trying to enter the queue are discarded, regardless of what traffic they hold. This is known as tail drop—packets arriving after the tail of the queue are dropped.
Congestion-avoidance techniques monitor network traffic loads so that congestion can be anticipated and avoided before it becomes problematic. If congestion-avoidance techniques are not used and interface queues become full, packets trying to enter the queue are discarded, regardless of what traffic they hold. This is known as tail drop—packets arriving after the tail of the queue are dropped.
![]() Congestion-avoidance techniques allow packets from streams identified as being eligible for early discard (those with lower priority) to be dropped when the queue is getting full.
Congestion-avoidance techniques allow packets from streams identified as being eligible for early discard (those with lower priority) to be dropped when the queue is getting full.
![]() Congestion avoidance works well with TCP-based traffic. TCP has a built-in flow control mechanism so that when a source detects a dropped packet, the source slows its transmission.
Congestion avoidance works well with TCP-based traffic. TCP has a built-in flow control mechanism so that when a source detects a dropped packet, the source slows its transmission.
![]() Weighted random early detection (WRED) is the Cisco implementation of the random early detection (RED) mechanism. RED randomly drops packets when the queue gets to a specified level (when it is nearing full). RED is designed to work with TCP traffic: When TCP packets are dropped, TCP’s flow-control mechanism slows the transmission rate and then progressively begins to increase it again. Therefore, RED results in sources slowing down and hopefully avoiding congestion.
Weighted random early detection (WRED) is the Cisco implementation of the random early detection (RED) mechanism. RED randomly drops packets when the queue gets to a specified level (when it is nearing full). RED is designed to work with TCP traffic: When TCP packets are dropped, TCP’s flow-control mechanism slows the transmission rate and then progressively begins to increase it again. Therefore, RED results in sources slowing down and hopefully avoiding congestion.
![]() WRED extends RED by using the IP precedence bits in the IP packet header to determine which traffic should be dropped; the drop-selection process is weighted by the IP precedence. Similarly, Differentiated Services Code Point (DSCP)–based WRED uses the DSCP value in the IP packet header in the drop-selection process. WRED selectively discards lower-priority traffic when the interface begins to get congested.
WRED extends RED by using the IP precedence bits in the IP packet header to determine which traffic should be dropped; the drop-selection process is weighted by the IP precedence. Similarly, Differentiated Services Code Point (DSCP)–based WRED uses the DSCP value in the IP packet header in the drop-selection process. WRED selectively discards lower-priority traffic when the interface begins to get congested.
![]() Starting in IOS Release 12.2(8)T, Cisco implemented an extension to WRED called explicit congestion notification (ECN). ECN is defined in RFC 3168, The Addition of Explicit Congestion Notification (ECN) to IP, and it uses the lower 2 bits in the ToS byte. Devices use these two ECN bits to communicate that they are experiencing congestion. When ECN is in use, it marks packets as experiencing congestion (rather than dropping them) if the senders are ECN-capable and the queue has not yet reached its maximum threshold. If the queue does reach the maximum, packets are dropped, as they would be without ECN.
Starting in IOS Release 12.2(8)T, Cisco implemented an extension to WRED called explicit congestion notification (ECN). ECN is defined in RFC 3168, The Addition of Explicit Congestion Notification (ECN) to IP, and it uses the lower 2 bits in the ToS byte. Devices use these two ECN bits to communicate that they are experiencing congestion. When ECN is in use, it marks packets as experiencing congestion (rather than dropping them) if the senders are ECN-capable and the queue has not yet reached its maximum threshold. If the queue does reach the maximum, packets are dropped, as they would be without ECN.
Traffic Shaping and Policing to Rate-Limit Traffic Classes
![]() Traffic shaping and traffic policing, illustrated in Figure 5-14, also referred to as committed access rate, are similar mechanisms in that both inspect traffic and take action based on the various characteristics of that traffic. These characteristics can be based on whether the traffic is over or under a given rate, or is based on some bits in the IP packet header, such as the DSCP or IP precedence.
Traffic shaping and traffic policing, illustrated in Figure 5-14, also referred to as committed access rate, are similar mechanisms in that both inspect traffic and take action based on the various characteristics of that traffic. These characteristics can be based on whether the traffic is over or under a given rate, or is based on some bits in the IP packet header, such as the DSCP or IP precedence.


![]() Policing either discards the packet or modifies some aspect of it, such as its IP precedence, when the policing agent determines that the packet meets a given criterion.
Policing either discards the packet or modifies some aspect of it, such as its IP precedence, when the policing agent determines that the packet meets a given criterion.
![]() For example, an enterprise’s policy management scheme could deem the traffic generated by a particular resource (such as the first 100 kbps) as first-class traffic, so it receives a top priority marking. Traffic above the first 100 kbps generated by that same resource could drop to a lower priority class or be discarded altogether. Similarly, all incoming streaming Moving Picture Experts Group (MPEG)-1 Audio Layer 3 (MP3) traffic could be limited to, for example, 10 percent of all available bandwidth so that it does not starve other applications.
For example, an enterprise’s policy management scheme could deem the traffic generated by a particular resource (such as the first 100 kbps) as first-class traffic, so it receives a top priority marking. Traffic above the first 100 kbps generated by that same resource could drop to a lower priority class or be discarded altogether. Similarly, all incoming streaming Moving Picture Experts Group (MPEG)-1 Audio Layer 3 (MP3) traffic could be limited to, for example, 10 percent of all available bandwidth so that it does not starve other applications.
![]() By comparison, traffic shaping attempts to adjust the transmission rate of packets that match a certain criterion.
By comparison, traffic shaping attempts to adjust the transmission rate of packets that match a certain criterion.
![]() Topologies that have high-speed links (such as a central site) feeding into lower-speed links (such as a remote or branch site) often experience bottlenecks at the remote end because of the speed mismatch. Traffic shaping helps eliminate the bottleneck situation by throttling back traffic volume at the source end. It reduces the flow of outbound traffic from a router interface by holding packets in a buffer and releasing them at a preconfigured rate; routers can be configured to transmit at a lower bit rate than the interface bit rate.
Topologies that have high-speed links (such as a central site) feeding into lower-speed links (such as a remote or branch site) often experience bottlenecks at the remote end because of the speed mismatch. Traffic shaping helps eliminate the bottleneck situation by throttling back traffic volume at the source end. It reduces the flow of outbound traffic from a router interface by holding packets in a buffer and releasing them at a preconfigured rate; routers can be configured to transmit at a lower bit rate than the interface bit rate.
![]() One common use of traffic shaping in the enterprise is to smooth the flow of traffic across a single link toward a service provider transport network to ensure compliance with the traffic contract, avoiding service provider policing at the receiving end. Traffic shaping reduces the bursty nature of the transmitted data and is most useful when the contract rate is less than the line rate. Traffic shaping can also respond to signaled congestion from the transport network when the traffic rates exceed the contract rate.
One common use of traffic shaping in the enterprise is to smooth the flow of traffic across a single link toward a service provider transport network to ensure compliance with the traffic contract, avoiding service provider policing at the receiving end. Traffic shaping reduces the bursty nature of the transmitted data and is most useful when the contract rate is less than the line rate. Traffic shaping can also respond to signaled congestion from the transport network when the traffic rates exceed the contract rate.
![]() A term you might encounter related to traffic shaping and policing is a token bucket. In the token bucket analogy, tokens are put into the bucket at a certain rate, and the bucket itself has a specified capacity. If the bucket fills to capacity, newly arriving tokens are discarded. Each token is permission for the source to send a certain number of bits into the network. To send a packet, the shaper or policer must remove from the bucket a number of tokens equal in representation to the packet size.
A term you might encounter related to traffic shaping and policing is a token bucket. In the token bucket analogy, tokens are put into the bucket at a certain rate, and the bucket itself has a specified capacity. If the bucket fills to capacity, newly arriving tokens are discarded. Each token is permission for the source to send a certain number of bits into the network. To send a packet, the shaper or policer must remove from the bucket a number of tokens equal in representation to the packet size.
![]() If not enough tokens are in the bucket to send a packet, the packet either waits until the bucket has enough tokens or the packet is discarded or marked down. If the bucket is already full of tokens, incoming tokens overflow and are not available to future packets. Consequently, at any time, the largest burst a source can send into the network is roughly proportional to the size of the bucket.
If not enough tokens are in the bucket to send a packet, the packet either waits until the bucket has enough tokens or the packet is discarded or marked down. If the bucket is already full of tokens, incoming tokens overflow and are not available to future packets. Consequently, at any time, the largest burst a source can send into the network is roughly proportional to the size of the bucket.
![]() Note that the token bucket mechanism used for traffic shaping has both a token bucket and a data buffer, or queue; if it did not have a data buffer, it would be a policer. For traffic shaping, arriving packets that cannot be sent immediately are delayed in the data buffer.
Note that the token bucket mechanism used for traffic shaping has both a token bucket and a data buffer, or queue; if it did not have a data buffer, it would be a policer. For traffic shaping, arriving packets that cannot be sent immediately are delayed in the data buffer.
![]() The information in this sidebar was derived from the Cisco IOS Quality of Service Solutions Configuration Guide, Release 12.2, available at http://www.cisco.com/en/US/products/sw/iosswrel/ps1835/products_configuration_guide_book09186a00800c5e31.html.
The information in this sidebar was derived from the Cisco IOS Quality of Service Solutions Configuration Guide, Release 12.2, available at http://www.cisco.com/en/US/products/sw/iosswrel/ps1835/products_configuration_guide_book09186a00800c5e31.html.
Using WAN Technologies
![]() Numerous WAN technologies exist today, and new technologies are constantly emerging. The most appropriate WAN selection usually results in high efficiency and leads to customer satisfaction. The network designer must be aware of all possible WAN design choices while taking into account customer requirements. This section describes the use of various WAN technologies, including the following:
Numerous WAN technologies exist today, and new technologies are constantly emerging. The most appropriate WAN selection usually results in high efficiency and leads to customer satisfaction. The network designer must be aware of all possible WAN design choices while taking into account customer requirements. This section describes the use of various WAN technologies, including the following:
- Remote access
- VPNs
- WAN backup
- The Internet as a backup WAN
Remote Access Network Design
![]() When you’re designing remote-access networks for teleworkers and traveling employees, the type of connection drives the technology selection, such as whether to choose a data link or a network layer connection. By analyzing the application requirements and service provider offerings, you can choose the most suitable of a wide range of remote-access technologies. Typical remote-access requirements include the following:
When you’re designing remote-access networks for teleworkers and traveling employees, the type of connection drives the technology selection, such as whether to choose a data link or a network layer connection. By analyzing the application requirements and service provider offerings, you can choose the most suitable of a wide range of remote-access technologies. Typical remote-access requirements include the following:
- Data link layer WAN technologies from remote sites to the Enterprise Edge network. Investment and operating costs are the main issues.
- Low- to medium-volume data file transfer and interactive traffic.
- Increasing need to support voice services.
![]() Remote access to the Enterprise Edge network is typically provided over permanent connections for remote teleworkers through a dedicated circuit or a provisioned service, or on-demand connections for traveling workers.
Remote access to the Enterprise Edge network is typically provided over permanent connections for remote teleworkers through a dedicated circuit or a provisioned service, or on-demand connections for traveling workers.
![]() Remote-access technology selections include dialup (both analog and digital), DSL, cable, and hot-spot wireless service.
Remote-access technology selections include dialup (both analog and digital), DSL, cable, and hot-spot wireless service.
![]() Dial-on-demand routing is a technique whereby a router can dynamically initiate and close a circuit-switched session when transmitting end-station demands. A router is configured to consider certain traffic interesting (such as traffic from a particular protocol) and other traffic uninteresting. When the router receives interesting traffic destined for a remote network, a circuit is established, and the traffic is transmitted normally. If the router receives uninteresting traffic and a circuit is already established, that traffic is also transmitted normally. The router maintains an idle timer that is reset only when it receives interesting traffic. If the router does not receive any interesting traffic before the idle timer expires, the circuit is terminated. Likewise, if the router receives uninteresting traffic and no circuit exists, the router drops the traffic.
Dial-on-demand routing is a technique whereby a router can dynamically initiate and close a circuit-switched session when transmitting end-station demands. A router is configured to consider certain traffic interesting (such as traffic from a particular protocol) and other traffic uninteresting. When the router receives interesting traffic destined for a remote network, a circuit is established, and the traffic is transmitted normally. If the router receives uninteresting traffic and a circuit is already established, that traffic is also transmitted normally. The router maintains an idle timer that is reset only when it receives interesting traffic. If the router does not receive any interesting traffic before the idle timer expires, the circuit is terminated. Likewise, if the router receives uninteresting traffic and no circuit exists, the router drops the traffic.
VPN Design
![]() A VPN is connectivity deployed on a shared infrastructure with the same policies, security, and performance as a private network, but typically with lower total cost of ownership.
A VPN is connectivity deployed on a shared infrastructure with the same policies, security, and performance as a private network, but typically with lower total cost of ownership.
![]() The infrastructure used can be the Internet, an IP infrastructure, or any WAN infrastructure, such as a Frame Relay network or an ATM WAN.
The infrastructure used can be the Internet, an IP infrastructure, or any WAN infrastructure, such as a Frame Relay network or an ATM WAN.
![]() The following sections discuss these topics:
The following sections discuss these topics:
VPN Applications
![]() VPNs can be grouped according to their applications:
VPNs can be grouped according to their applications:
- Access VPN: Access VPNs provide access to a corporate intranet (or extranet) over a shared infrastructure and have the same policies as a private network. Remote-access connectivity is through dial-up, ISDN, DSL, wireless, or cable technologies. Access VPNs enable businesses to outsource their dial or other broadband remote access connections without compromising their security policy.The two access VPN architectures are client-initiated and Network Access Server (NAS)–initiated connections. With client-initiated VPNs, users establish an encrypted IP tunnel from their PCs across an SP’s shared network to their corporate network. With NAS-initiated VPNs, the tunnel is initiated from the NAS; in this scenario, remote users dial into the local SP point of presence (POP), and the SP initiates a secure, encrypted tunnel to the corporate network.
- Intranet VPN: Intranet VPNs link remote offices by extending the corporate network across a shared infrastructure. The intranet VPN services are typically based on extending the basic remote-access VPN to other corporate offices across the Internet or across the SP’s IP backbone. Note that there are no performance guarantees with VPNs across the Internet—no one organization is responsible for the performance of the Internet. The main benefits of intranet VPNs are reduced WAN infrastructure needs, which result in lower ongoing leased-line, Frame Relay, or other WAN charges, and operational savings.
- Extranet VPN: Extranet VPNs extend the connectivity to business partners, suppliers, and customers across the Internet or an SP’s network. The security policy becomes very important at this point; for example, the company does not want a hacker to spoof any orders from a business partner. The main benefits of an extranet VPN are the ease of securely connecting a business partner as needed, and the ease of severing the connection with the business partner (partner today, competitor tomorrow), which becomes as simple as shutting down the VPN tunnel. Very granular rules can be created for what traffic is shared with the peer network in the extranet.
VPN Connectivity Options
![]() The following sections describe three connectivity options that provide IP access through VPNs:
The following sections describe three connectivity options that provide IP access through VPNs:
Overlay VPNs
![]() With overlay VPNs, the provider’s infrastructure provides virtual point-to-point links between customer sites. Overlay VPNs are implemented with a number of technologies, including traditional Layer 1 and Layer 2 technologies (such as ISDN, SONET/SDH, Frame Relay, and ATM) overlaid with modern Layer 3 IP-based solutions (such as Generic Routing Encapsulation [GRE] and IPsec).
With overlay VPNs, the provider’s infrastructure provides virtual point-to-point links between customer sites. Overlay VPNs are implemented with a number of technologies, including traditional Layer 1 and Layer 2 technologies (such as ISDN, SONET/SDH, Frame Relay, and ATM) overlaid with modern Layer 3 IP-based solutions (such as Generic Routing Encapsulation [GRE] and IPsec).
![]() From the Layer 3 perspective, the provider network is invisible: The customer routers are linked with emulated point-to-point links. The routing protocol runs directly between routers that establish routing adjacencies and exchange routing information. The provider is not aware of customer routing and does not have any information about customer routes. The provider’s only responsibility is the point-to-point data transport between customer sites. Although they are well known and easy to implement, overlay VPNs are more difficult to operate and have higher maintenance costs for the following reasons:
From the Layer 3 perspective, the provider network is invisible: The customer routers are linked with emulated point-to-point links. The routing protocol runs directly between routers that establish routing adjacencies and exchange routing information. The provider is not aware of customer routing and does not have any information about customer routes. The provider’s only responsibility is the point-to-point data transport between customer sites. Although they are well known and easy to implement, overlay VPNs are more difficult to operate and have higher maintenance costs for the following reasons:
- Every individual virtual circuit must be provisioned.
- Optimum routing between customer sites requires a full mesh of virtual circuits between sites.
- Bandwidth must be provisioned on a site-to-site basis.
![]() The concept of VPNs was introduced early in the emergence of data communications with technologies such as X.25 and Frame Relay. These technologies use virtual circuits to establish the end-to-end connection over a shared SP infrastructure. In the case of overlay VPNs, emulated point-to-point links replace the dedicated links, and the provider infrastructure is statistically shared. Overlay VPNs enable the provider to offer the connectivity for a lower price and result in lower operational costs.
The concept of VPNs was introduced early in the emergence of data communications with technologies such as X.25 and Frame Relay. These technologies use virtual circuits to establish the end-to-end connection over a shared SP infrastructure. In the case of overlay VPNs, emulated point-to-point links replace the dedicated links, and the provider infrastructure is statistically shared. Overlay VPNs enable the provider to offer the connectivity for a lower price and result in lower operational costs.
![]() Figure 5-15 illustrates an overlay VPN. The router on the left (in the Enterprise Edge module) has one physical connection to the SP, with two virtual circuits provisioned. Virtual Circuit 1 (VC #1) provides connectivity to the router on the top right. Virtual Circuit 2 (VC #2) provides connectivity to the branch office router on the bottom right.
Figure 5-15 illustrates an overlay VPN. The router on the left (in the Enterprise Edge module) has one physical connection to the SP, with two virtual circuits provisioned. Virtual Circuit 1 (VC #1) provides connectivity to the router on the top right. Virtual Circuit 2 (VC #2) provides connectivity to the branch office router on the bottom right.


VPDNs
![]() VPDNs enable an enterprise to configure secure networks that rely on an ISP for connectivity. With VPDNs, the customers use a provider’s dial-in (or other type of connectivity) infrastructure for their private connections. A VPDN can be used with any available access technology. Ubiquity is important, meaning that VPDNs should work with any technology, including a modem, ISDN, xDSL, or cable connections.
VPDNs enable an enterprise to configure secure networks that rely on an ISP for connectivity. With VPDNs, the customers use a provider’s dial-in (or other type of connectivity) infrastructure for their private connections. A VPDN can be used with any available access technology. Ubiquity is important, meaning that VPDNs should work with any technology, including a modem, ISDN, xDSL, or cable connections.
![]() The ISP agrees to forward the company’s traffic from the ISP’s POP to a company-run home gateway. Network configuration and security remain in the client’s control. The SP supplies a virtual tunnel between the company’s sites using Cisco Layer 2 Forwarding, point-to-point tunneling, or IETF Layer 2 Tunneling Protocol (L2TP) tunnels.
The ISP agrees to forward the company’s traffic from the ISP’s POP to a company-run home gateway. Network configuration and security remain in the client’s control. The SP supplies a virtual tunnel between the company’s sites using Cisco Layer 2 Forwarding, point-to-point tunneling, or IETF Layer 2 Tunneling Protocol (L2TP) tunnels.
![]() Figure 5-16 illustrates a VPDN. In this figure, the ISP terminates the dialup connections at the L2TP Access Concentrator (LAC) and forwards traffic through dynamically established tunnels to a remote access server called the L2TP Network Server (LNS). A VPDN provides potential operations and infrastructure cost savings because a company can outsource its dialup equipment, thereby avoiding the costs of being in the remote access server business.
Figure 5-16 illustrates a VPDN. In this figure, the ISP terminates the dialup connections at the L2TP Access Concentrator (LAC) and forwards traffic through dynamically established tunnels to a remote access server called the L2TP Network Server (LNS). A VPDN provides potential operations and infrastructure cost savings because a company can outsource its dialup equipment, thereby avoiding the costs of being in the remote access server business.


![]() Access VPN connectivity involves the configuration of VPDN tunnels. Following are the two types of tunnels:
Access VPN connectivity involves the configuration of VPDN tunnels. Following are the two types of tunnels:
- The client PC initiates voluntary tunnels. The client dials into the SP network, a PPP session is established, and the user logs on to the SP network. The client then runs the VPN software to establish a tunnel to the network server.
- Compulsory tunnels require SP participation and awareness, giving the client no influence over tunnel selection. The client still dials in and establishes a PPP session, but the SP (not the client) establishes the tunnel to the network server.
Peer-to-Peer VPNs
![]() In a peer-to-peer VPN, the provider actively participates in customer routing.
In a peer-to-peer VPN, the provider actively participates in customer routing.
![]() Traditional peer-to-peer VPNs are implemented with packet filters on shared provider edge (PE) routers, or with dedicated per-customer PE routers. In addition to high maintenance costs for the packet filter approach or equipment costs for the dedicated per-customer PE-router approach, both methods require the customer to accept the provider-assigned address space or to use public IP addresses in the private customer network.
Traditional peer-to-peer VPNs are implemented with packet filters on shared provider edge (PE) routers, or with dedicated per-customer PE routers. In addition to high maintenance costs for the packet filter approach or equipment costs for the dedicated per-customer PE-router approach, both methods require the customer to accept the provider-assigned address space or to use public IP addresses in the private customer network.
![]() Modern MPLS VPNs provide all the benefits of peer-to-peer VPNs and alleviate most of the peer-to-peer VPN drawbacks such as the need for common customer addresses. Overlapping addresses, which are usually the result of companies using private addressing, are one of the major obstacles to successful peer-to-peer VPN implementations. MPLS VPNs solve this problem by giving each VPN its own routing and forwarding table in the router, thus effectively creating virtual routers for each customer.
Modern MPLS VPNs provide all the benefits of peer-to-peer VPNs and alleviate most of the peer-to-peer VPN drawbacks such as the need for common customer addresses. Overlapping addresses, which are usually the result of companies using private addressing, are one of the major obstacles to successful peer-to-peer VPN implementations. MPLS VPNs solve this problem by giving each VPN its own routing and forwarding table in the router, thus effectively creating virtual routers for each customer.
| Note |
|
![]() With MPLS VPNs, networks are learned via static route configuration or with a routing protocol such as OSPF, EIGRP, Routing Information Protocol (RIP) version 2 (RIPv2), or Border Gateway Protocol (BGP) from other internal routers. As described in the earlier “MPLS” section, MPLS uses a label to identify a flow of packets. MPLS VPNs use an additional label to specify the VPN and the corresponding VPN destination network, allowing for overlapping addresses between VPNs.
With MPLS VPNs, networks are learned via static route configuration or with a routing protocol such as OSPF, EIGRP, Routing Information Protocol (RIP) version 2 (RIPv2), or Border Gateway Protocol (BGP) from other internal routers. As described in the earlier “MPLS” section, MPLS uses a label to identify a flow of packets. MPLS VPNs use an additional label to specify the VPN and the corresponding VPN destination network, allowing for overlapping addresses between VPNs.
Benefits of VPNs
![]() The benefits of using VPNs include the following:
The benefits of using VPNs include the following:
- Flexibility: VPNs offer flexibility because site-to-site and remote-access connections can be set up quickly and over existing infrastructure to extend the network to remote users. Extranet connectivity for business partners is also a possibility. A variety of security policies can be provisioned in a VPN, thereby enabling flexible interconnection of different security domains.
- Scalability: VPNs allow an organization to leverage and extend the classic WAN to more remote and external users. VPNs offer scalability over large areas because IP transport is universally available. This arrangement reduces the number of physical connections and simplifies the underlying structure of a customer’s WAN.
- Lower network communication cost: Lower cost is a primary reason for migrating from traditional connectivity options to a VPN connection. Reduced dialup and dedicated bandwidth infrastructure and service provider costs make VPNs attractive. Customers can reuse existing links and take advantage of the statistical packet multiplexing features.
WAN Backup Strategies
![]() This section describes various backup options for providing alternative paths for remote access. WAN links are relatively unreliable compared to LAN links and often are much slower than the LANs to which they connect. This combination of uncertain reliability, lack of speed, and high importance makes WAN links good candidates for redundancy to achieve high availability.
This section describes various backup options for providing alternative paths for remote access. WAN links are relatively unreliable compared to LAN links and often are much slower than the LANs to which they connect. This combination of uncertain reliability, lack of speed, and high importance makes WAN links good candidates for redundancy to achieve high availability.
![]() Branch offices should experience minimum downtime in case of primary link failure. A backup connection can be established, either via dialup or by using permanent connections. The main WAN backup options are as follows:
Branch offices should experience minimum downtime in case of primary link failure. A backup connection can be established, either via dialup or by using permanent connections. The main WAN backup options are as follows:
![]() The following sections describe these options.
The following sections describe these options.
Dial Backup Routing
![]() Dial backup routing is a way of using a dialup service for backup purposes. In this scenario, the switched circuit provides the backup service for another type of circuit, such as point-to-point or Frame Relay. The router initiates the dial backup line when it detects a failure on the primary circuit. The dial backup line provides WAN connectivity until the primary circuit is restored, at which time the dial backup connection terminates.
Dial backup routing is a way of using a dialup service for backup purposes. In this scenario, the switched circuit provides the backup service for another type of circuit, such as point-to-point or Frame Relay. The router initiates the dial backup line when it detects a failure on the primary circuit. The dial backup line provides WAN connectivity until the primary circuit is restored, at which time the dial backup connection terminates.
Permanent Secondary WAN Link
![]() Deploying an additional permanent WAN link between each remote office and the central office makes the network more fault-tolerant. This solution offers the following two advantages:
Deploying an additional permanent WAN link between each remote office and the central office makes the network more fault-tolerant. This solution offers the following two advantages:
- Provides a backup link: The backup link is used if a primary link that connects any remote office with the central office fails. Routers automatically route around failed WAN links by using floating static routes and routing protocols, such as EIGRP and OSPF. If one link fails, the router recalculates and sends all traffic through another link, allowing applications to proceed if a WAN link fails, thereby improving application availability.
Note A floating static route is one that appears in the routing table only when the primary route goes away. The administrative distance of the static route is configured to be higher than the administrative distance of the primary route, and it “floats” above the primary route until the primary route is no longer available. - Increased bandwidth: Both the primary and secondary links can be used simultaneously because they are permanent. The routing protocol automatically performs load balancing between two parallel links with equal costs (or unequal costs if EIGRP is used). The resulting increased bandwidth decreases response times.
![]() Cost is the primary disadvantage of duplicating WAN links to each remote office. For example, in addition to new equipment, including new WAN router interfaces, a large star network with 20 remote sites might need 20 new virtual circuits.
Cost is the primary disadvantage of duplicating WAN links to each remote office. For example, in addition to new equipment, including new WAN router interfaces, a large star network with 20 remote sites might need 20 new virtual circuits.
![]() In Figure 5-17, the connections between the Enterprise Edge and remote sites use permanent primary and secondary WAN links for redundancy. A routing protocol, such as EIGRP, that supports load balancing over unequal paths on either a per-packet or per-destination basis is used to increase the utilization of the backup link.
In Figure 5-17, the connections between the Enterprise Edge and remote sites use permanent primary and secondary WAN links for redundancy. A routing protocol, such as EIGRP, that supports load balancing over unequal paths on either a per-packet or per-destination basis is used to increase the utilization of the backup link.
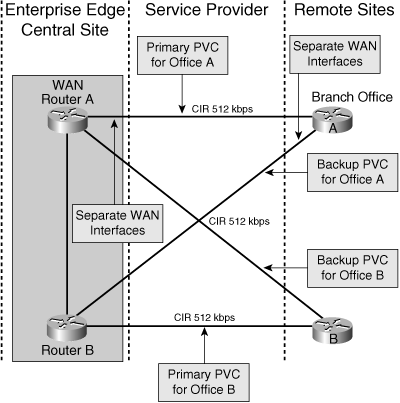
![]() If the WAN connections are relatively slow (less than 56 kbps), per-packet load balancing should be used. Load balancing occurs on a per-destination basis when fast switching is enabled, which is appropriate on WAN connections faster than 56 kbps.
If the WAN connections are relatively slow (less than 56 kbps), per-packet load balancing should be used. Load balancing occurs on a per-destination basis when fast switching is enabled, which is appropriate on WAN connections faster than 56 kbps.
![]() During process switching, the router examines the incoming packet and looks up the Layer 3 address in the routing table, which is located in main memory, to associate this address with a destination network or subnet. Process switching is a scheduled process performed by the system processor. Compared to other switching modes, process switching is slow because of the latency caused by scheduling and the latency within the process itself.
During process switching, the router examines the incoming packet and looks up the Layer 3 address in the routing table, which is located in main memory, to associate this address with a destination network or subnet. Process switching is a scheduled process performed by the system processor. Compared to other switching modes, process switching is slow because of the latency caused by scheduling and the latency within the process itself.
![]() With fast switching, an incoming packet matches an entry in the fast-switching cache (also called the route cache), which is located in main memory. This cache is populated when the first packet to the destination is process-switched. Fast switching is done via asynchronous interrupts, which are handled in real time and result in higher throughput.
With fast switching, an incoming packet matches an entry in the fast-switching cache (also called the route cache), which is located in main memory. This cache is populated when the first packet to the destination is process-switched. Fast switching is done via asynchronous interrupts, which are handled in real time and result in higher throughput.
![]() Other switching modes are available on some routers (including Autonomous Switching, Silicon Switching, Optimum Switching, Distributed Switching, and NetFlow Switching). Cisco Express Forwarding (CEF) technology, described in Chapter 4, is the latest advance in Cisco IOS switching capabilities for IP.
Other switching modes are available on some routers (including Autonomous Switching, Silicon Switching, Optimum Switching, Distributed Switching, and NetFlow Switching). Cisco Express Forwarding (CEF) technology, described in Chapter 4, is the latest advance in Cisco IOS switching capabilities for IP.
Shadow PVC
![]() With shadow PVCs, as long as the maximum load on the shadow PVC does not exceed a certain rate (such as one-fourth of the primary speed) while the primary PVC is available, the SP provides a secondary PVC without any additional charge. If the traffic limit on the shadow PVC is exceeded while the primary PVC is up, the SP charges for the excess load on the shadow PVC.
With shadow PVCs, as long as the maximum load on the shadow PVC does not exceed a certain rate (such as one-fourth of the primary speed) while the primary PVC is available, the SP provides a secondary PVC without any additional charge. If the traffic limit on the shadow PVC is exceeded while the primary PVC is up, the SP charges for the excess load on the shadow PVC.
![]() Figure 5-18 illustrates redundant connections between remotes sites and the Enterprise Edge using the shadow PVCs offered by the SP. Because of the potential for additional costs, the routers must avoid sending any unnecessary data (except, for example, routing traffic) over the shadow PVC.
Figure 5-18 illustrates redundant connections between remotes sites and the Enterprise Edge using the shadow PVCs offered by the SP. Because of the potential for additional costs, the routers must avoid sending any unnecessary data (except, for example, routing traffic) over the shadow PVC.

The Internet as a WAN Backup Technology
![]() This section describes the Internet as an alternative option for a failed WAN connection. This type of connection is considered best-effort and does not guarantee any bandwidth. Common methods for connecting noncontiguous private networks over a public IP network include the following:
This section describes the Internet as an alternative option for a failed WAN connection. This type of connection is considered best-effort and does not guarantee any bandwidth. Common methods for connecting noncontiguous private networks over a public IP network include the following:
![]() The following sections describe these methods.
The following sections describe these methods.
IP Routing Without Constraints
![]() When relying on the Internet to provide a backup for branch offices, a company must fully cooperate with the ISP and announce its networks. The backup network—the Internet—therefore becomes aware of the company’s data, because it is sent unencrypted.
When relying on the Internet to provide a backup for branch offices, a company must fully cooperate with the ISP and announce its networks. The backup network—the Internet—therefore becomes aware of the company’s data, because it is sent unencrypted.
Layer 3 Tunneling with GRE and IPsec
![]() Layer 3 tunneling uses a Layer 3 protocol to transport over another Layer 3 network. Typically, Layer 3 tunneling is used either to connect two noncontiguous parts of a non-IP network over an IP network or to connect two IP networks over a backbone IP network, possibly hiding the IP addressing details of the two networks from the backbone IP network. Following are the two Layer 3 tunneling methods for connecting noncontiguous private networks over a public IP network:
Layer 3 tunneling uses a Layer 3 protocol to transport over another Layer 3 network. Typically, Layer 3 tunneling is used either to connect two noncontiguous parts of a non-IP network over an IP network or to connect two IP networks over a backbone IP network, possibly hiding the IP addressing details of the two networks from the backbone IP network. Following are the two Layer 3 tunneling methods for connecting noncontiguous private networks over a public IP network:
- GRE: A protocol developed by Cisco that encapsulates a wide variety of packet types inside IP tunnels. GRE is designed for generic tunneling of protocols. In the Cisco IOS, GRE tunnels IP over IP, which can be useful when building a small-scale IP VPN network that does not require substantial security.GRE enables simple and flexible deployment of basic IP VPNs. Deployment is easy; however, tunnel provisioning is not very scalable in a full-mesh network because every point-to-point association must be defined separately. The packet payload is not protected against sniffing and unauthorized changes (no encryption is used), and no sender authentication occurs.Using GRE tunnels as a mechanism for backup links has several drawbacks, including administrative overhead, scaling to large numbers of tunnels, and processing overhead of the GRE encapsulation.
- IPsec: IPsec is both a tunnel encapsulation protocol and a security protocol. IPsec provides security for the transmission of sensitive information over unprotected networks (such as the Internet) by encrypting the tunnel’s data. IPsec acts as the network layer in tunneling or transport mode and protects and authenticates IP packets between participating IPsec devices. Following are some features of IPsec:
- Data confidentiality: An IPsec sender can encrypt packets before transmitting them across a network.
- Data integrity: An IPsec receiver can authenticate packets sent by an IPsec sender to ensure that the data has not been altered during transmission.
- Data origin authentication: An IPsec receiver can authenticate the source of the sent IPsec packets. This service depends on the data integrity service.
- Anti-replay: An IPsec receiver can detect and reject replay by rejecting old or duplicate packets.
- Easy deployment: IPsec can be deployed with no change to the intermediate systems (the ISP backbone) and no change to existing applications (it is transparent to applications).
- Internet Key Exchange (IKE): IPsec uses IKE for automated key management.
- Public Key Infrastructure (PKI): IPsec is interoperable with PKI.
-
![]() IPsec can be combined with GRE tunnels to provide security in GRE tunnels; for example, the GRE payload (the IP packet) would be encrypted.
IPsec can be combined with GRE tunnels to provide security in GRE tunnels; for example, the GRE payload (the IP packet) would be encrypted.
| Note |
|
![]() Because it is standards-based, IPsec allows Cisco devices to interoperate with other non-Cisco IPsec-compliant networking devices, including PCs and servers. IPsec also allows the use of digital certificates using the IKE protocol and certification authorities (CA). A digital certificate contains information to identify a user or device, such as the name, serial number, company, or IP address. It also contains a copy of the device’s public key. The CA, which is a third party that the receiver explicitly trusts to validate identities and create digital certificates, signs the certificate. When using digital certificates, each device is enrolled with a CA. When two devices want to communicate, they exchange certificates and digitally sign data to authenticate each other. Manual exchange and verification of keys are not required.
Because it is standards-based, IPsec allows Cisco devices to interoperate with other non-Cisco IPsec-compliant networking devices, including PCs and servers. IPsec also allows the use of digital certificates using the IKE protocol and certification authorities (CA). A digital certificate contains information to identify a user or device, such as the name, serial number, company, or IP address. It also contains a copy of the device’s public key. The CA, which is a third party that the receiver explicitly trusts to validate identities and create digital certificates, signs the certificate. When using digital certificates, each device is enrolled with a CA. When two devices want to communicate, they exchange certificates and digitally sign data to authenticate each other. Manual exchange and verification of keys are not required.
![]() When a new device is added to the network, it must simply enroll with a CA; none of the other devices need modification. When the new device attempts an IPsec connection, certificates are automatically exchanged, and the device can be authenticated.
When a new device is added to the network, it must simply enroll with a CA; none of the other devices need modification. When the new device attempts an IPsec connection, certificates are automatically exchanged, and the device can be authenticated.
![]() Figure 5-19 illustrates two noncontiguous networks connected over a point-to-point logical link with a backup implemented over an IP network using a GRE IP tunnel. Such tunnels are configured between a source (ingress) router and a destination (egress) router and are visible as interfaces on each router.
Figure 5-19 illustrates two noncontiguous networks connected over a point-to-point logical link with a backup implemented over an IP network using a GRE IP tunnel. Such tunnels are configured between a source (ingress) router and a destination (egress) router and are visible as interfaces on each router.


![]() Data to be forwarded across the tunnel is already formatted in a packet, encapsulated in the standard IP packet header. This packet is further encapsulated with a new GRE header and placed into the tunnel with the destination IP address set to the tunnel endpoint, the new next hop. When the GRE packet reaches the tunnel endpoint, the GRE header is stripped away and the packet continues to be forwarded to the destination with the original IP packet header.
Data to be forwarded across the tunnel is already formatted in a packet, encapsulated in the standard IP packet header. This packet is further encapsulated with a new GRE header and placed into the tunnel with the destination IP address set to the tunnel endpoint, the new next hop. When the GRE packet reaches the tunnel endpoint, the GRE header is stripped away and the packet continues to be forwarded to the destination with the original IP packet header.
0 comments
Post a Comment