
![]() This chapter explains the benefits of structured troubleshooting and identifies the leading principles that are at the core of all troubleshooting methodologies. Implementing troubleshooting procedures is the next topic, with a discussion on gathering and analyzing information and solving the problem. Finally, the generic troubleshooting processes and their relation to network maintenance processes are analyzed along with the role of change control and documentation.
This chapter explains the benefits of structured troubleshooting and identifies the leading principles that are at the core of all troubleshooting methodologies. Implementing troubleshooting procedures is the next topic, with a discussion on gathering and analyzing information and solving the problem. Finally, the generic troubleshooting processes and their relation to network maintenance processes are analyzed along with the role of change control and documentation.
 Troubleshooting Methodologies
Troubleshooting Methodologies
![]() Troubleshooting is not an exact science, and a particular problem can be diagnosed and sometimes even solved in many different ways. However, when you perform structured troubleshooting, you make continuous progress, and usually solve the problems faster than it would take using an ad hoc approach. There are many different structured troubleshooting approaches. For some problems, one method might work better, whereas for others, another method might be more suitable. Therefore, it is beneficial for the troubleshooter to be familiar with a variety of structured approaches and select the best method or combination of methods to solve a particular problem.
Troubleshooting is not an exact science, and a particular problem can be diagnosed and sometimes even solved in many different ways. However, when you perform structured troubleshooting, you make continuous progress, and usually solve the problems faster than it would take using an ad hoc approach. There are many different structured troubleshooting approaches. For some problems, one method might work better, whereas for others, another method might be more suitable. Therefore, it is beneficial for the troubleshooter to be familiar with a variety of structured approaches and select the best method or combination of methods to solve a particular problem.
Troubleshooting Principles
![]() Troubleshooting is the process that leads to the diagnosis and, if possible, resolution of a problem. Troubleshooting is usually triggered when a person reports a problem. Some people say that a problem does not exist until it is noticed, perceived as a problem, and reported as a problem. This implies that you need to differentiate between a problem, as experienced by the user, and the actual cause of that problem. The time a problem is reported is not necessarily the same time at which the event causing the problem happened. Also, the reporting user generally equates the problem to the symptoms, whereas the troubleshooter often equates the problem to the root cause. For example, if the Internet connection fails on Saturday in a small company, it is usually not a problem, but you can be sure that it will turn into a problem on Monday morning if it is not fixed before then. Although this distinction between symptoms and cause of a problem might seem philosophical, you need to be aware of the potential communication issues that might arise from it.
Troubleshooting is the process that leads to the diagnosis and, if possible, resolution of a problem. Troubleshooting is usually triggered when a person reports a problem. Some people say that a problem does not exist until it is noticed, perceived as a problem, and reported as a problem. This implies that you need to differentiate between a problem, as experienced by the user, and the actual cause of that problem. The time a problem is reported is not necessarily the same time at which the event causing the problem happened. Also, the reporting user generally equates the problem to the symptoms, whereas the troubleshooter often equates the problem to the root cause. For example, if the Internet connection fails on Saturday in a small company, it is usually not a problem, but you can be sure that it will turn into a problem on Monday morning if it is not fixed before then. Although this distinction between symptoms and cause of a problem might seem philosophical, you need to be aware of the potential communication issues that might arise from it.
![]() Generally, reporting of a problem triggers the troubleshooting process. Troubleshooting starts by defining the problem. The second step is diagnosing the problem during which information is gathered, the problem definition is refined, and possible causes for the problem are proposed. Eventually this process should lead to a hypothesis for the root cause of the problem. At this time, possible solutions need to be proposed and evaluated. Next, the best solution is selected and implemented. Figure 2-1 illustrates the main elements of a structured troubleshooting approach and the transition possibilities from one step to the next.
Generally, reporting of a problem triggers the troubleshooting process. Troubleshooting starts by defining the problem. The second step is diagnosing the problem during which information is gathered, the problem definition is refined, and possible causes for the problem are proposed. Eventually this process should lead to a hypothesis for the root cause of the problem. At this time, possible solutions need to be proposed and evaluated. Next, the best solution is selected and implemented. Figure 2-1 illustrates the main elements of a structured troubleshooting approach and the transition possibilities from one step to the next.


![]() It is noteworthy, however, that the solution to a network problem cannot always be readily implemented and an interim workaround might have to be proposed. The difference between a solution and a workaround is that a solution resolves the root cause of the problem, whereas a workaround only alleviates the symptoms of the problem.
It is noteworthy, however, that the solution to a network problem cannot always be readily implemented and an interim workaround might have to be proposed. The difference between a solution and a workaround is that a solution resolves the root cause of the problem, whereas a workaround only alleviates the symptoms of the problem.
![]() Although problem reporting and resolution are definitely essential elements of the troubleshooting process, most of the time is spent in the diagnostic phase. One might even believe that diagnosis is all troubleshooting is about. Nevertheless, within the context of network maintenance, problem reporting and resolution are indeed essential parts of troubleshooting. Diagnosis is the process of identifying the nature and cause of a problem. The main elements of this process are as follows:
Although problem reporting and resolution are definitely essential elements of the troubleshooting process, most of the time is spent in the diagnostic phase. One might even believe that diagnosis is all troubleshooting is about. Nevertheless, within the context of network maintenance, problem reporting and resolution are indeed essential parts of troubleshooting. Diagnosis is the process of identifying the nature and cause of a problem. The main elements of this process are as follows:
- Gathering information: Gathering information happens after the problem has been reported by the user (or anyone). This might include interviewing all parties (user) involved, plus any other means to gather relevant information. Usually, the problem report does not contain enough information to formulate a good hypothesis without first gathering more information. Information and symptoms can be gathered directly, by observing processes, or indirectly, by executing tests.
- Analyzing information: After the gathered information has been analyzed, the troubleshooter compares the symptoms against his knowledge of the system, processes, and baselines to separate normal behavior from abnormal behavior.
- Eliminating possible causes: By comparing the observed behavior against expected behavior, some of the possible problems causes are eliminated.
- Formulating a hypothesis: After gathering and analyzing information and eliminating the possible causes, one or more potential problem causes remain. The probability of each of these causes will have to be assessed and the most likely cause proposed as the hypothetical cause of the problem.
- Testing the hypothesis: The hypothesis must be tested to confirm or deny that it is the actual cause of the problem. The simplest way to do this is by proposing a solution based on this hypothesis, implementing that solution, and verifying whether this solved the problem. If this method is impossible or disruptive, the hypothesis can be strengthened or invalidated by gathering and analyzing more information.
![]() All troubleshooting methods include the elements of gathering and analyzing information, eliminating possible causes, and formulating and testing hypotheses. Each of these steps has its merits and requires some time and effort; how and when one moves from one step to the next is a key factor in the success level of a troubleshooting exercise. In a scenario where you are troubleshooting a complex problem, you might go back and forth between different stages of troubleshooting—Gather some information, analyze the information, eliminate some of the possibilities, gather more information, analyze again, formulate a hypothesis, test it, reject it, eliminate some more possibilities, gather more information, and so on.
All troubleshooting methods include the elements of gathering and analyzing information, eliminating possible causes, and formulating and testing hypotheses. Each of these steps has its merits and requires some time and effort; how and when one moves from one step to the next is a key factor in the success level of a troubleshooting exercise. In a scenario where you are troubleshooting a complex problem, you might go back and forth between different stages of troubleshooting—Gather some information, analyze the information, eliminate some of the possibilities, gather more information, analyze again, formulate a hypothesis, test it, reject it, eliminate some more possibilities, gather more information, and so on.
![]() If you do not take a structured approach to troubleshooting and go through its steps back and forth in an ad hoc fashion, you might eventually find the solution; however, the process in general will be very inefficient. Another drawback of this approach is that handing the job over to someone else is very hard to do; the progress results are mainly lost. This can happen even if the troubleshooter wants to resume his own task after he has stopped for a while, perhaps to take care of another matter. A structured approach to troubleshooting, regardless of the exact method adopted, yields more predictable results in the long run. It also makes it easier to pick up where you left off or hand the job over to someone else without losing any effort or results. A troubleshooting method that is commonly deployed both by inexperienced and experienced troubleshooters is the shoot-from-the-hip method. Using this method, after a very short period of gathering information, the troubleshooter quickly makes a change to see if it solves the problem. Even though it may seem like random troubleshooting on the surface, it is not. The reason is that the guiding principle for this method is knowledge of common symptoms and their corresponding causes, or simply extensive relevant experience in a particular environment or application. This technique might be quite effective for the experienced troubleshooter most times, but it usually does not yield the same results for the inexperienced troubleshooter. Figure 2-2 shows how the “shoot from the hip” goes about solving a problem, spending almost no effort in analyzing the gathered information and eliminating possibilities.
If you do not take a structured approach to troubleshooting and go through its steps back and forth in an ad hoc fashion, you might eventually find the solution; however, the process in general will be very inefficient. Another drawback of this approach is that handing the job over to someone else is very hard to do; the progress results are mainly lost. This can happen even if the troubleshooter wants to resume his own task after he has stopped for a while, perhaps to take care of another matter. A structured approach to troubleshooting, regardless of the exact method adopted, yields more predictable results in the long run. It also makes it easier to pick up where you left off or hand the job over to someone else without losing any effort or results. A troubleshooting method that is commonly deployed both by inexperienced and experienced troubleshooters is the shoot-from-the-hip method. Using this method, after a very short period of gathering information, the troubleshooter quickly makes a change to see if it solves the problem. Even though it may seem like random troubleshooting on the surface, it is not. The reason is that the guiding principle for this method is knowledge of common symptoms and their corresponding causes, or simply extensive relevant experience in a particular environment or application. This technique might be quite effective for the experienced troubleshooter most times, but it usually does not yield the same results for the inexperienced troubleshooter. Figure 2-2 shows how the “shoot from the hip” goes about solving a problem, spending almost no effort in analyzing the gathered information and eliminating possibilities.


![]() Assume that a user reports a LAN performance problem and in 90 percent of the past cases with similar symptoms, the problem has been caused by duplex mismatch between users’ workstation (PC or laptop) and the corresponding access switch port. The solution has been to configure the switch port for 100-Mbps full duplex. Therefore, it sounds reasonable to quickly verify the duplex setting of the switch port to which the user connects and change it to 100-Mbps full duplex to see whether that fixes the problem. When it works, this method can be very effective because it takes very little time. Unfortunately, the downside of this method is that if it does not work, you have not come any closer to a possible solution, you have wasted some time (both yours and users’), and you might possibly have caused a bit of frustration. Experienced troubleshooters use this method to great effect. The key factor in using this method effectively is knowing when to stop and switch to a more methodical (structured) approach.
Assume that a user reports a LAN performance problem and in 90 percent of the past cases with similar symptoms, the problem has been caused by duplex mismatch between users’ workstation (PC or laptop) and the corresponding access switch port. The solution has been to configure the switch port for 100-Mbps full duplex. Therefore, it sounds reasonable to quickly verify the duplex setting of the switch port to which the user connects and change it to 100-Mbps full duplex to see whether that fixes the problem. When it works, this method can be very effective because it takes very little time. Unfortunately, the downside of this method is that if it does not work, you have not come any closer to a possible solution, you have wasted some time (both yours and users’), and you might possibly have caused a bit of frustration. Experienced troubleshooters use this method to great effect. The key factor in using this method effectively is knowing when to stop and switch to a more methodical (structured) approach.
Structured Troubleshooting Approaches
![]() A structured troubleshooting method is used as a guideline through a troubleshooting process. The key to all structured troubleshooting methods is systematic elimination of hypothetical causes and narrowing down on the possible causes. By systematically eliminating possible problem causes, you can reduce the scope of the problem until you manage to isolate and solve the problem. If at some point you decide to seek help or hand the task over to someone else, your findings can be of help to that person and your efforts are not wasted.
A structured troubleshooting method is used as a guideline through a troubleshooting process. The key to all structured troubleshooting methods is systematic elimination of hypothetical causes and narrowing down on the possible causes. By systematically eliminating possible problem causes, you can reduce the scope of the problem until you manage to isolate and solve the problem. If at some point you decide to seek help or hand the task over to someone else, your findings can be of help to that person and your efforts are not wasted.
![]() Commonly used troubleshooting approaches include the following:
Commonly used troubleshooting approaches include the following:
- Top down: Using this approach, you work from the Open Systems Interconnection (OSI) model’s application layer down to the physical layer.
- Bottom up: The bottom-up approach starts from the OSI model’s physical layer and moves up to the application layer.
- Divide and conquer: Using this approach, you start in the middle of the OSI model’s stack (usually the network layer) and then, based on your findings, you move up or down the OSI stack.
- Follow the path: This approach is based on the path that packets take through the network from source to destination.
- Spot the differences: As the name implies, this approach compares network devices or processes that are operating correctly to devices or processes that are not operating as expected and gathers clues by spotting significant differences. In case the problem occurred after a change on a single device was implemented, the spot-the-differences approach can pinpoint the problem cause by focusing on the difference between the device configurations, before and after the problem was reported.
- Move the problem: The strategy of this troubleshooting approach is to physically move components and observe whether the problem moves with the components.
![]() The sections that follow describe each of these methods in greater detail.
The sections that follow describe each of these methods in greater detail.
Top-Down Troubleshooting Method
![]() The top-down troubleshooting method uses the OSI model as a guiding principle. One of the most important characteristics of the OSI model is that each layer depends on the underlying layers for its operation. This implies that if you find a layer to be operational, you can safely assume that all underlying layers are fully operational as well. So for instance, if you are researching a problem of a user that cannot browse a particular website and you find that you can establish a TCP connection on port 80 from this host to the server and get a response from the server, you can typically draw the conclusion that the transport layer and all layers below must be fully functional between the client and the server and that this is most likely a client or server problem and not a network problem. Be aware that in this example it is reasonable to conclude that Layers 1 through 4 must be fully operational, but it does not definitively prove this. For instance, non-fragmented packets might be routed correctly, while fragmented packets are dropped. The TCP connection to port 80 might not uncover such a problem. Essentially, the goal of this method is to find the highest OSI layer that is still working. All devices and processes that work on that layer or layers below are then eliminated from the scope of the problem. It might be clear that this method is most effective if the problem is on one of the higher OSI layers. This approach is also one of the most straightforward troubleshooting methods, because problems reported by users are typically defined as application layer problems, so starting the troubleshooting process at that layer is an obvious thing to do. A drawback or impediment to this method is that you need to have access to the client’s application layer software to initiate the troubleshooting process, and if the software is only installed on a small number of machines, your troubleshooting options might be limited.
The top-down troubleshooting method uses the OSI model as a guiding principle. One of the most important characteristics of the OSI model is that each layer depends on the underlying layers for its operation. This implies that if you find a layer to be operational, you can safely assume that all underlying layers are fully operational as well. So for instance, if you are researching a problem of a user that cannot browse a particular website and you find that you can establish a TCP connection on port 80 from this host to the server and get a response from the server, you can typically draw the conclusion that the transport layer and all layers below must be fully functional between the client and the server and that this is most likely a client or server problem and not a network problem. Be aware that in this example it is reasonable to conclude that Layers 1 through 4 must be fully operational, but it does not definitively prove this. For instance, non-fragmented packets might be routed correctly, while fragmented packets are dropped. The TCP connection to port 80 might not uncover such a problem. Essentially, the goal of this method is to find the highest OSI layer that is still working. All devices and processes that work on that layer or layers below are then eliminated from the scope of the problem. It might be clear that this method is most effective if the problem is on one of the higher OSI layers. This approach is also one of the most straightforward troubleshooting methods, because problems reported by users are typically defined as application layer problems, so starting the troubleshooting process at that layer is an obvious thing to do. A drawback or impediment to this method is that you need to have access to the client’s application layer software to initiate the troubleshooting process, and if the software is only installed on a small number of machines, your troubleshooting options might be limited.
Bottom-Up Troubleshooting Method
![]() The bottom-up troubleshooting approach also uses the OSI model as its guiding principle with the physical layer (bottom layer of the OSI stack) as the starting point. In this approach you work your way layer by layer up toward the application layer, and verify that relevant network elements are operating correctly. You try to eliminate more and more potential problem causes so that you can narrow down the scope of the potential problems. A benefit of this method is that all of the initial troubleshooting takes place on the network, so access to clients, servers, or applications is not necessary until a very late stage in the troubleshooting process. Based on experience, you will find that most network problems are hardware related. If this is applicable to your environment, the bottom-up approach will be most suitable for you. A disadvantage of this method is that, in large networks, it can be a time-consuming process, because a lot of effort will be spent on gathering and analyzing data and you always start from the bottom layer. The best bottom-up approach is to first reduce the scope of the problem using a different strategy and then switch to the bottom-up approach for clearly bounded parts of the network topology.
The bottom-up troubleshooting approach also uses the OSI model as its guiding principle with the physical layer (bottom layer of the OSI stack) as the starting point. In this approach you work your way layer by layer up toward the application layer, and verify that relevant network elements are operating correctly. You try to eliminate more and more potential problem causes so that you can narrow down the scope of the potential problems. A benefit of this method is that all of the initial troubleshooting takes place on the network, so access to clients, servers, or applications is not necessary until a very late stage in the troubleshooting process. Based on experience, you will find that most network problems are hardware related. If this is applicable to your environment, the bottom-up approach will be most suitable for you. A disadvantage of this method is that, in large networks, it can be a time-consuming process, because a lot of effort will be spent on gathering and analyzing data and you always start from the bottom layer. The best bottom-up approach is to first reduce the scope of the problem using a different strategy and then switch to the bottom-up approach for clearly bounded parts of the network topology.
Divide-and-Conquer Troubleshooting Method
![]() The divide-and-conquer troubleshooting method strikes a balance between the top-down and bottom-up troubleshooting approaches. If it is not clear which of the top-down or bottom-up approaches will be more effective for a particular problem, an alternative is to start in the middle (typically the network layer) and perform some tests such as ping. Ping is an excellent connectivity testing tool. If the test is successful, you can assume that all lower layers are functional, and so you can start a bottom-up troubleshooting starting from this layer. However, if the test fails, you can start a top-down troubleshooting starting from this layer. Whether the result of the initial test is positive or negative, this method will usually result in a faster elimination of potential problems than what you would achieve by implementing a full top-down or bottom-up approach. Therefore, the divide-and-conquer method is considered a highly effective troubleshooting approach.
The divide-and-conquer troubleshooting method strikes a balance between the top-down and bottom-up troubleshooting approaches. If it is not clear which of the top-down or bottom-up approaches will be more effective for a particular problem, an alternative is to start in the middle (typically the network layer) and perform some tests such as ping. Ping is an excellent connectivity testing tool. If the test is successful, you can assume that all lower layers are functional, and so you can start a bottom-up troubleshooting starting from this layer. However, if the test fails, you can start a top-down troubleshooting starting from this layer. Whether the result of the initial test is positive or negative, this method will usually result in a faster elimination of potential problems than what you would achieve by implementing a full top-down or bottom-up approach. Therefore, the divide-and-conquer method is considered a highly effective troubleshooting approach.
Follow-the-Path Troubleshooting Method
![]() The follow-the-path approach is one of the most basic troubleshooting techniques, and it usually complements one of the other troubleshooting methods such as the top-down or the bottom-up approach. The follow-the-path approach first discovers the actual traffic path all the way from source to destination. Next, the scope of troubleshooting is reduced to just the links and devices that are actually in the forwarding path. The principle of this approach is to eliminate the links and devices that are irrelevant to the troubleshooting task at hand.
The follow-the-path approach is one of the most basic troubleshooting techniques, and it usually complements one of the other troubleshooting methods such as the top-down or the bottom-up approach. The follow-the-path approach first discovers the actual traffic path all the way from source to destination. Next, the scope of troubleshooting is reduced to just the links and devices that are actually in the forwarding path. The principle of this approach is to eliminate the links and devices that are irrelevant to the troubleshooting task at hand.
Spot-the-Differences Troubleshooting Method
![]() Another common troubleshooting approach is called spotting the differences. By comparing configurations, software versions, hardware, or other device properties, links, or processes between working and nonworking situations and spotting significant differences between them, this approach attempts to resolve the problem by changing the non-operational elements to be consistent with the working ones. The weakness of this method is that it might lead to a working situation, without clearly revealing the root cause of the problem. In some cases, you are not sure whether you have implemented a solution or a workaround. Example 2-1 shows two routing tables; one belongs to Branch2, experiencing problems, and the other belongs to Branch1, with no problems. If you compare the content of these routing tables, as per the spotting-the-differences approach, a natural deduction is that the branch with problems is missing a static entry. The static entry can be added to see whether it solves the problem.
Another common troubleshooting approach is called spotting the differences. By comparing configurations, software versions, hardware, or other device properties, links, or processes between working and nonworking situations and spotting significant differences between them, this approach attempts to resolve the problem by changing the non-operational elements to be consistent with the working ones. The weakness of this method is that it might lead to a working situation, without clearly revealing the root cause of the problem. In some cases, you are not sure whether you have implemented a solution or a workaround. Example 2-1 shows two routing tables; one belongs to Branch2, experiencing problems, and the other belongs to Branch1, with no problems. If you compare the content of these routing tables, as per the spotting-the-differences approach, a natural deduction is that the branch with problems is missing a static entry. The static entry can be added to see whether it solves the problem.
Branch1# show ip route
<...output omitted...>
10.0.0.0/24 is subnetted, 1 subnets
C 10.132.125.0 is directly connected, FastEthernet4
C 192.168.36.0/24 is directly connected, BVI1
S* 0.0.0.0/0 [254/0] via 10.132.125.1
————————————- Branch2 has connectivity problems ——————————
Branch2# show ip route
<...output omitted...>
10.0.0.0/24 is subnetted, 1 subnets
C 10.132.126.0 is directly connected, FastEthernet4
C 192.168.37.0/24 is directly connected, BVI1
![]() To further illustrate the spotting-the-differences approach and highlight its shortcomings, assume that you are troubleshooting a connectivity problem with a branch office router and you have managed to narrow down the problem to some issue with the DSL link. You have not discovered the real culprit, but you notice that this branch’s router is an older type that was phased out in most of the other branch offices. In the trunk of your car, you have a newer type of router that must be installed at another branch office next week. You decide to copy the configuration of the existing malfunctioning branch router to the new router and use the new router at this branch. Now everything works to your satisfaction, but unfortunately, the following questions remain unanswered:
To further illustrate the spotting-the-differences approach and highlight its shortcomings, assume that you are troubleshooting a connectivity problem with a branch office router and you have managed to narrow down the problem to some issue with the DSL link. You have not discovered the real culprit, but you notice that this branch’s router is an older type that was phased out in most of the other branch offices. In the trunk of your car, you have a newer type of router that must be installed at another branch office next week. You decide to copy the configuration of the existing malfunctioning branch router to the new router and use the new router at this branch. Now everything works to your satisfaction, but unfortunately, the following questions remain unanswered:
- Is the problem actually fixed?
- What was the root cause of the problem?
- What should you do with the old router?
- What will you do for the branch that was supposed to receive the new router you just used?
![]() In a case like this, the default settings (and behavior) of the old and the newer operating systems (IOS) could be different, and that explains why using the newer router solves the problem at hand. Unless those differences are analyzed, explained, and documented (that is, communicated to others), merely changing the routers is not considered a solution to the problem, and the questions in the preceding list remain unanswered.
In a case like this, the default settings (and behavior) of the old and the newer operating systems (IOS) could be different, and that explains why using the newer router solves the problem at hand. Unless those differences are analyzed, explained, and documented (that is, communicated to others), merely changing the routers is not considered a solution to the problem, and the questions in the preceding list remain unanswered.
![]() Obviously, the spotting-the-differences method has a number of drawbacks, but what still makes it useful is that you can use it even when you lack the proper technological and troubleshooting knowledge and background. The effectiveness of this method depends heavily on how easy it is to compare working and nonworking device, situations, or processes. Having a good baseline of what constitutes normal behavior on the network makes it easier to spot abnormal behavior. Also, the use of consistent configuration templates makes it easier to spot the significant differences between functioning and malfunctioning devices. Consequently, the effectiveness of this method depends on the quality of the overall network maintenance process. Similar to the follow the path approach, spot the differences is best used as a supporting method in combination with other troubleshooting approaches.
Obviously, the spotting-the-differences method has a number of drawbacks, but what still makes it useful is that you can use it even when you lack the proper technological and troubleshooting knowledge and background. The effectiveness of this method depends heavily on how easy it is to compare working and nonworking device, situations, or processes. Having a good baseline of what constitutes normal behavior on the network makes it easier to spot abnormal behavior. Also, the use of consistent configuration templates makes it easier to spot the significant differences between functioning and malfunctioning devices. Consequently, the effectiveness of this method depends on the quality of the overall network maintenance process. Similar to the follow the path approach, spot the differences is best used as a supporting method in combination with other troubleshooting approaches.
Move-the-Problem Troubleshooting Method
![]() Move the problem is a very elementary troubleshooting technique that can be used for problem isolation: You physically swap components and observe whether the problem stays in place, moves with the component, or disappears entirely. Figure 2-3 shows two PCs and three laptops connected to a LAN switch, among which laptop B has connectivity problems. Assuming that hardware failure is suspected, you must discover if the problem is on the switch, the cable, or the laptop. One approach is to start gathering data by checking the settings on the laptop with problems, examining the settings on the switch, comparing the settings of all the laptops, and the switch ports, and so on. However, you might not have the required administrative passwords for the PCs, laptops, and the switch. The only data that you can gather is the status of the link LEDs on the switch and the laptops and PCs. What you can do is obviously limited. A common way to at least isolate the problem (if it is not solved outright) is cable or port swapping. Swap the cable between a working device and laptop B (the one that is having problems). Move the laptop from one port to another using a cable that you know for sure is good. Based on these simple moves, you can isolate whether the problem is cable, switch, or laptop related.
Move the problem is a very elementary troubleshooting technique that can be used for problem isolation: You physically swap components and observe whether the problem stays in place, moves with the component, or disappears entirely. Figure 2-3 shows two PCs and three laptops connected to a LAN switch, among which laptop B has connectivity problems. Assuming that hardware failure is suspected, you must discover if the problem is on the switch, the cable, or the laptop. One approach is to start gathering data by checking the settings on the laptop with problems, examining the settings on the switch, comparing the settings of all the laptops, and the switch ports, and so on. However, you might not have the required administrative passwords for the PCs, laptops, and the switch. The only data that you can gather is the status of the link LEDs on the switch and the laptops and PCs. What you can do is obviously limited. A common way to at least isolate the problem (if it is not solved outright) is cable or port swapping. Swap the cable between a working device and laptop B (the one that is having problems). Move the laptop from one port to another using a cable that you know for sure is good. Based on these simple moves, you can isolate whether the problem is cable, switch, or laptop related.
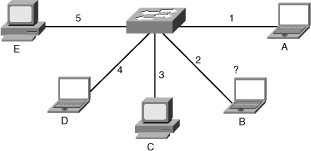
![]() Just by executing simple tests in a methodical way, the move-the-problem approach enables you to isolate the problem even if the information that you can gather is minimal. Even if you do not solve the problem, you have scoped it to a single element, and you can now focus further troubleshooting on that element. Note that in the previous example if you determine that the problem is cable related, it is unnecessary to obtain the administrative password for the switch, PCs, and laptops. The drawbacks of this method is that you are isolating the problem to only a limited set of physical elements and not gaining any real insight in what is happening, because you are gathering only very limited indirect information. This method assumes that the problem is with a single component. If the problem lies within multiple devices, you might not be able to isolate the problem correctly.
Just by executing simple tests in a methodical way, the move-the-problem approach enables you to isolate the problem even if the information that you can gather is minimal. Even if you do not solve the problem, you have scoped it to a single element, and you can now focus further troubleshooting on that element. Note that in the previous example if you determine that the problem is cable related, it is unnecessary to obtain the administrative password for the switch, PCs, and laptops. The drawbacks of this method is that you are isolating the problem to only a limited set of physical elements and not gaining any real insight in what is happening, because you are gathering only very limited indirect information. This method assumes that the problem is with a single component. If the problem lies within multiple devices, you might not be able to isolate the problem correctly.
Troubleshooting Example: Methodologies
![]() An external financial consultant has come in to help your company’s controller with an accounting problem. He needs access to the finance server. An account has been created for him on the server, and the client software has been installed on the consultant’s laptop. You happen to walk past the controller’s office and are called in and told that the consultant can’t connect to the finance server. You are a network support engineer and have access to all network devices, but not to the servers. Think about how you would handle this problem, what your troubleshooting plan would be, and which method or combination of methods you would use.
An external financial consultant has come in to help your company’s controller with an accounting problem. He needs access to the finance server. An account has been created for him on the server, and the client software has been installed on the consultant’s laptop. You happen to walk past the controller’s office and are called in and told that the consultant can’t connect to the finance server. You are a network support engineer and have access to all network devices, but not to the servers. Think about how you would handle this problem, what your troubleshooting plan would be, and which method or combination of methods you would use.
![]() What possible approaches can you take for this troubleshooting task? This case lends itself to many different approaches, but some specific characteristics can help you decide an appropriate approach:
What possible approaches can you take for this troubleshooting task? This case lends itself to many different approaches, but some specific characteristics can help you decide an appropriate approach:
- You have access to the network devices, but not to the server. This implies that you will likely be able to handle Layer 1–4 problems by yourself; however, for Layer 5–7, you will probably have to escalate to a different person.
- You have access to the client device, so it is possible to start your troubleshooting from it.
- The controller has the same software and access rights on his machine, so it is possible to compare between the two devices.
![]() What are the benefits and drawbacks of each possible troubleshooting approach for this case?
What are the benefits and drawbacks of each possible troubleshooting approach for this case?
- Top down: You have the opportunity to start testing at the application layer. It is good troubleshooting practice to confirm the reported problem, so starting from the application layer is an obvious choice. The only possible drawback is that you will not discover simple problems, such as the cable being plugged in to a wrong outlet, until later in the process.
- Bottom up: A full bottom-up check of the whole network is not a very useful approach because it will take too much time and at this point, there is no reason to assume that the network beyond the first access switch would be causing the issue. You could consider starting with a bottom-up approach for the first stretch of the network, from the consultant’s laptop to the access switch, to uncover potential cabling problems.
- Divide and conquer: This is a viable approach. You can ping from the consultant’s laptop to the finance server. If that succeeds, you know that the problem is more likely to be with the application (although you have to consider potential firewall problems, too). If the ping fails, you are definitely dealing with a network issue, and you are responsible for fixing it. The advantage of this method is that you can quickly decide on the scope of the problem and whether escalation is necessary.
- Follow the path: Similar to the bottom-up approach, a full follow-the-path approach is not efficient under the circumstances, but tracing the cabling to the first switch can be a good start if it turns out that the link LED is off on the consultant’s PC. This method might come into play after other techniques have been used to narrow the scope of the problem.
- Spot the differences: You have access to both the controller’s PC and the consultant’s laptop; therefore, spot the differences is a possible strategy. However, because these machines are not under the control of a single IT department, you might find many differences, and it might therefore be hard to spot the significant and relevant differences. Spot the differences might prove useful later, after it has been determined that the problem is likely to be on the client.
- Move the problem: Using this approach alone is not likely to be enough to solve the problem, but if following any of the other methods indicates a potential hardware issue between the consultant’s PC and the access switch, this method might come into play. However, merely as a first step, you could consider swapping the cable and the jack connected to the consultant’s laptop and the controller’s PC, in turn, to see whether the problem is cable, PC, or switch related.
![]() Many combinations of these different methods could be considered here. The most promising methods are top down or divide and conquer. You will possibly switch to follow-the-path or spot-the-differences approach after the scope of the problem has been properly reduced. As an initial step in any approach, the move-the-problem method could be used to quickly separate client-related issues from network-related issues. The bottom-up approach could be used as the first step to verify the first stretch of cabling.
Many combinations of these different methods could be considered here. The most promising methods are top down or divide and conquer. You will possibly switch to follow-the-path or spot-the-differences approach after the scope of the problem has been properly reduced. As an initial step in any approach, the move-the-problem method could be used to quickly separate client-related issues from network-related issues. The bottom-up approach could be used as the first step to verify the first stretch of cabling.
3 comments
I know Laura well and she is principled, thoughtful, and extremely bright...more power to her!
123 hp setup
Hey Shalu, Do you know Laura well?
123.hp.com printer setup | 123.hp.com/setup
hp officejet pro 8715 install
hp officejet pro 6978 troubleshooting
1hp officejet 3830 wireless setup
hp officejet pro 6968 setup
hp officejet pro 6975 wireless setup
Really awesome blog. Your blog is really useful for me. Thanks for sharing this informative blog. Keep update your blog.
hp officejet pro 6975 setup
Post a Comment