
Implementing Troubleshooting Procedures
![]() The troubleshooting process can be guided by structured methods, but it is not static, and its steps are not always the same and may not be executed in the exact same order every time. Each network is different, each problem is different, and the skill set and experience of the engineer involved in a troubleshooting process is different. However, to guarantee a certain level of consistency in the way that problems are diagnosed and solved in an organization, it is still important to evaluate the common subprocesses that are part of troubleshooting and define procedures that outline how they should be handled. The generic troubleshooting process consists of the following tasks:
The troubleshooting process can be guided by structured methods, but it is not static, and its steps are not always the same and may not be executed in the exact same order every time. Each network is different, each problem is different, and the skill set and experience of the engineer involved in a troubleshooting process is different. However, to guarantee a certain level of consistency in the way that problems are diagnosed and solved in an organization, it is still important to evaluate the common subprocesses that are part of troubleshooting and define procedures that outline how they should be handled. The generic troubleshooting process consists of the following tasks:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]() It is important to analyze the typical actions and decisions that are taken during each of these processes and how these could be planned and implemented as troubleshooting procedures.
It is important to analyze the typical actions and decisions that are taken during each of these processes and how these could be planned and implemented as troubleshooting procedures.
 The Troubleshooting Process
The Troubleshooting Process
![]() A network troubleshooting process can be reduced to a number of elementary subprocesses, as outlined in the preceding list. These subprocesses are not strictly sequential in nature, and many times you will go back and forth through many of these subprocesses repeatedly until you eventually reach the solving-the-problem phase. A troubleshooting method provides a guiding principle that helps you move through these processes in a structured way. There is no exact recipe for troubleshooting. Every problem is different, and it is impossible to create a script that will solve all possible problem scenarios. Troubleshooting is a skill that requires relevant knowledge and experience. After using different methods several times, you will become more effective at selecting the right method for a particular problem, gathering the most relevant information, and analyzing problems quickly and efficiently. As you gain more experience, you will find that you can skip some steps and adopt more of a shoot-from-the-hip approach, resolving problems more quickly. Regardless, to execute a successful troubleshooting exercise, you must be able to answer the following questions:
A network troubleshooting process can be reduced to a number of elementary subprocesses, as outlined in the preceding list. These subprocesses are not strictly sequential in nature, and many times you will go back and forth through many of these subprocesses repeatedly until you eventually reach the solving-the-problem phase. A troubleshooting method provides a guiding principle that helps you move through these processes in a structured way. There is no exact recipe for troubleshooting. Every problem is different, and it is impossible to create a script that will solve all possible problem scenarios. Troubleshooting is a skill that requires relevant knowledge and experience. After using different methods several times, you will become more effective at selecting the right method for a particular problem, gathering the most relevant information, and analyzing problems quickly and efficiently. As you gain more experience, you will find that you can skip some steps and adopt more of a shoot-from-the-hip approach, resolving problems more quickly. Regardless, to execute a successful troubleshooting exercise, you must be able to answer the following questions:
- What is the action plan for each of the elementary subprocesses or phases?
- What is it that you actually do during each of those subprocesses?
- What kind of support or resources do you need?
- What kind of communication needs to take place?
- How do you assign proper responsibilities?
![]() Although the answers to these questions will differ for each individual organization, by planning, documenting, and implementing troubleshooting procedures, the consistency and effectiveness of the troubleshooting processes in your organization will improve.
Although the answers to these questions will differ for each individual organization, by planning, documenting, and implementing troubleshooting procedures, the consistency and effectiveness of the troubleshooting processes in your organization will improve.
Defining the Problem
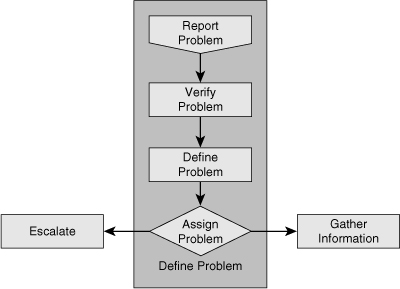
![]() All troubleshooting tasks begin with defining the problem. However, what triggers a troubleshooting exercise is a failure experienced by someone who reports it to the support group. Figure 2-4 illustrates reporting of the problem (done by the user) as the trigger action, followed by verification and defining the problem (done by support group). Unless an organization has a strict policy on how problems are reported, the reported problem can unfortunately be vague or even misleading. Problem reports can look like the following: “When I try to go to this location on the intranet, I get a page that says I don’t have permission,” “The mail server isn’t working,” or “I can’t file my expense report.” As you might have noticed, the second statement is merely a conclusion a user has drawn perhaps merely because he cannot send or receive e-mail. To prevent wasting a lot of time during the troubleshooting process based on false assumptions and claims, the first step of troubleshooting is always verifying and defining the problem. The problem has to be first verified, and then defined by you (the support engineer, not the user), and it has to be defined clearly.
All troubleshooting tasks begin with defining the problem. However, what triggers a troubleshooting exercise is a failure experienced by someone who reports it to the support group. Figure 2-4 illustrates reporting of the problem (done by the user) as the trigger action, followed by verification and defining the problem (done by support group). Unless an organization has a strict policy on how problems are reported, the reported problem can unfortunately be vague or even misleading. Problem reports can look like the following: “When I try to go to this location on the intranet, I get a page that says I don’t have permission,” “The mail server isn’t working,” or “I can’t file my expense report.” As you might have noticed, the second statement is merely a conclusion a user has drawn perhaps merely because he cannot send or receive e-mail. To prevent wasting a lot of time during the troubleshooting process based on false assumptions and claims, the first step of troubleshooting is always verifying and defining the problem. The problem has to be first verified, and then defined by you (the support engineer, not the user), and it has to be defined clearly.
![]() A good problem description consists of accurate descriptions of symptoms and not of interpretations or conclusions. Consequences for the user are strictly not part of the problem description itself, but can be helpful to assess the urgency of the issue. When a problem is reported as “The mail server isn’t working,” you must perhaps contact the user and find out exactly what he has experienced. You will probably define the problem as “When user X starts his e-mail client, he gets an error message saying that the client can not connect to the server. The user can still access his network drives and browse the Internet.”
A good problem description consists of accurate descriptions of symptoms and not of interpretations or conclusions. Consequences for the user are strictly not part of the problem description itself, but can be helpful to assess the urgency of the issue. When a problem is reported as “The mail server isn’t working,” you must perhaps contact the user and find out exactly what he has experienced. You will probably define the problem as “When user X starts his e-mail client, he gets an error message saying that the client can not connect to the server. The user can still access his network drives and browse the Internet.”
![]() After you have clearly defined the problem, you have one more step to take before starting the actual troubleshooting process. You must determine whether this problem is your responsibility or if it needs to be escalated to another department or person. For example, assume the reported problem is this: “When user Y tries to access the corporate directory on the company intranet, she gets a message that says permission is denied. She can access all other intranet pages.” You are a network engineer, and you do not have access to the servers. A separate department in your company manages the intranet servers. Therefore, you must know what to do when this type of problem is reported to you as a network problem. You must know whether to start troubleshooting or to escalate it to the server department. It is important that you know which type of problems is your responsibility to act on, what minimal actions you need to take before you escalate a problem, and how you escalate a problem. As Figure 2-4 illustrates, after defining the problem, you assign the problem: The problem is either escalated to another group or department, or it is network support’s responsibility to solve it. In the latter case, the next step is gathering and analyzing information.
After you have clearly defined the problem, you have one more step to take before starting the actual troubleshooting process. You must determine whether this problem is your responsibility or if it needs to be escalated to another department or person. For example, assume the reported problem is this: “When user Y tries to access the corporate directory on the company intranet, she gets a message that says permission is denied. She can access all other intranet pages.” You are a network engineer, and you do not have access to the servers. A separate department in your company manages the intranet servers. Therefore, you must know what to do when this type of problem is reported to you as a network problem. You must know whether to start troubleshooting or to escalate it to the server department. It is important that you know which type of problems is your responsibility to act on, what minimal actions you need to take before you escalate a problem, and how you escalate a problem. As Figure 2-4 illustrates, after defining the problem, you assign the problem: The problem is either escalated to another group or department, or it is network support’s responsibility to solve it. In the latter case, the next step is gathering and analyzing information.
Gathering and Analyzing Information
![]() Before gathering information, you should select your initial troubleshooting method and develop an information-gathering plan. As part of this plan, you need to identify what the targets are for the information-gathering process. In other words, you must decide which devices, clients, or servers you want to collect information from, and what tools you intend to use to gather that information (assemble a toolkit). Next, you have to acquire access to the identified targets. In many cases, you might have access to these systems as a normal part of your job role, but in some cases, you might need to get information from systems that you cannot normally access. In this case, you might have to escalate the issue to a different department or person, either to obtain access or to get someone else to gather the information for you. If the escalation process would slow the procedure down and the problem is urgent, you might want to reconsider the troubleshooting method that you selected and first try a method that uses different targets and would not require you to escalate. As you can see in Figure 2-5, whether you can access and examine the devices you identified will either lead to problems escalation to another group or department or to the gathering and analyzing information step.
Before gathering information, you should select your initial troubleshooting method and develop an information-gathering plan. As part of this plan, you need to identify what the targets are for the information-gathering process. In other words, you must decide which devices, clients, or servers you want to collect information from, and what tools you intend to use to gather that information (assemble a toolkit). Next, you have to acquire access to the identified targets. In many cases, you might have access to these systems as a normal part of your job role, but in some cases, you might need to get information from systems that you cannot normally access. In this case, you might have to escalate the issue to a different department or person, either to obtain access or to get someone else to gather the information for you. If the escalation process would slow the procedure down and the problem is urgent, you might want to reconsider the troubleshooting method that you selected and first try a method that uses different targets and would not require you to escalate. As you can see in Figure 2-5, whether you can access and examine the devices you identified will either lead to problems escalation to another group or department or to the gathering and analyzing information step.

![]() The example that follows demonstrates how information gathering can be influenced by factors out of your control, and consequently, force you to alter your troubleshooting approach. Imagine that it is 1.00 p.m. now and your company’s sales manager has reported that he cannot send or receive e-mail from the branch office where he is working. The matter is quite urgent because he has to send out a response to an important request for proposal (RFP) later this afternoon. Your first reaction might be to start a top-down troubleshooting method by calling him up and running through a series of tests. However, the sales manager is not available because he is in a meeting until 4:30 p.m. One of your colleagues from that same branch office confirms that the sales manager is in a meeting, but left his laptop on his desk. The RFP response needs to be received by the customer before 5:00 p.m. Even though a top-down troubleshooting approach might seem like the best choice, because you will not be able to access the sales manager’s laptop, you will have to wait until 4:30 before you can start troubleshooting. Having to perform an entire troubleshooting exercise successfully in about 30 minutes is risky, and it will put you under a lot of pressure. In this case, it is best if you used a combination of the “bottom-up” and “follow-the-path” approaches. You can verify whether there are any Layer 1–3 problems between the manager’s laptop and the company’s mail server. Even if you do not find an issue, you can eliminate many potential problem causes, and when you start a top-down approach at 4:30, you will be able to work more efficiently.
The example that follows demonstrates how information gathering can be influenced by factors out of your control, and consequently, force you to alter your troubleshooting approach. Imagine that it is 1.00 p.m. now and your company’s sales manager has reported that he cannot send or receive e-mail from the branch office where he is working. The matter is quite urgent because he has to send out a response to an important request for proposal (RFP) later this afternoon. Your first reaction might be to start a top-down troubleshooting method by calling him up and running through a series of tests. However, the sales manager is not available because he is in a meeting until 4:30 p.m. One of your colleagues from that same branch office confirms that the sales manager is in a meeting, but left his laptop on his desk. The RFP response needs to be received by the customer before 5:00 p.m. Even though a top-down troubleshooting approach might seem like the best choice, because you will not be able to access the sales manager’s laptop, you will have to wait until 4:30 before you can start troubleshooting. Having to perform an entire troubleshooting exercise successfully in about 30 minutes is risky, and it will put you under a lot of pressure. In this case, it is best if you used a combination of the “bottom-up” and “follow-the-path” approaches. You can verify whether there are any Layer 1–3 problems between the manager’s laptop and the company’s mail server. Even if you do not find an issue, you can eliminate many potential problem causes, and when you start a top-down approach at 4:30, you will be able to work more efficiently.
Eliminating Possible Problem Causes
![]() After gathering information from various devices, you must interpret and analyze the information. In a way, this process is similar to detective work. You must use the facts and evidence to progressively eliminate possible causes and eventually identify the root of the problem. To interpret the raw information that you have gathered, for example, the output of show and debug commands, or packet captures and device logs, you might need to research commands, protocols, and technologies. You might also need to consult network documentation to be able to interpret the information in the context of the actual network’s implementation. During the analysis of the gathered information, you are typically trying to determine two things: What is happening on the network and what should be happening. If you discover differences between these two, you can collect clues for what is wrong or at least a direction to take for further information gathering. Figure 2-6 shows that the gathered information, network documentation, baseline information, plus your research results and past experience are all used as input while you interpret and analyze the gathered information to eliminate possibilities and identify the source of the problem.
After gathering information from various devices, you must interpret and analyze the information. In a way, this process is similar to detective work. You must use the facts and evidence to progressively eliminate possible causes and eventually identify the root of the problem. To interpret the raw information that you have gathered, for example, the output of show and debug commands, or packet captures and device logs, you might need to research commands, protocols, and technologies. You might also need to consult network documentation to be able to interpret the information in the context of the actual network’s implementation. During the analysis of the gathered information, you are typically trying to determine two things: What is happening on the network and what should be happening. If you discover differences between these two, you can collect clues for what is wrong or at least a direction to take for further information gathering. Figure 2-6 shows that the gathered information, network documentation, baseline information, plus your research results and past experience are all used as input while you interpret and analyze the gathered information to eliminate possibilities and identify the source of the problem.


![]() Your perception of what is actually happening is usually formed based on interpretation of the raw data, supported by research and documentation; however, your understanding of the underlying protocols and technologies also plays a role in your success level. If you are troubleshooting protocols and technologies that you are not very familiar with, you will have to invest some time in researching how they operate. Furthermore, a good baseline of the behavior of your network can prove quite useful at the analysis stage. If you know how your network performs and how things work under normal conditions, you can spot anomalies in the behavior of the network and derive clues from those deviations. The benefit of vast relevant past experience cannot be undermined. An experienced network engineer will spend significantly less time on researching processes, interpreting raw data, and distilling the relevant information from the raw data than an inexperienced engineer.
Your perception of what is actually happening is usually formed based on interpretation of the raw data, supported by research and documentation; however, your understanding of the underlying protocols and technologies also plays a role in your success level. If you are troubleshooting protocols and technologies that you are not very familiar with, you will have to invest some time in researching how they operate. Furthermore, a good baseline of the behavior of your network can prove quite useful at the analysis stage. If you know how your network performs and how things work under normal conditions, you can spot anomalies in the behavior of the network and derive clues from those deviations. The benefit of vast relevant past experience cannot be undermined. An experienced network engineer will spend significantly less time on researching processes, interpreting raw data, and distilling the relevant information from the raw data than an inexperienced engineer.
Formulating/Testing a Hypothesis
![]() Figure 2-7 shows that based on your continuous information analysis and the assumptions you make, you eliminate possible problem causes from the pool of proposed causes until you have a final proposal that takes you to the next step of the troubleshooting process: formulating and proposing a hypothesis.
Figure 2-7 shows that based on your continuous information analysis and the assumptions you make, you eliminate possible problem causes from the pool of proposed causes until you have a final proposal that takes you to the next step of the troubleshooting process: formulating and proposing a hypothesis.


![]() After you have interpreted and analyzed the information that you have gathered, you start drawing conclusions from the results. On one hand, some of the discovered clues point toward certain issues that can be causing the problem, adding to your list of potential problem causes. For example, a very high CPU load on your multilayer switches can be a sign of a bridging loop. On the other hand, you might rule out some of the potential problem causes based on the gathered and analyzed facts. For example, a successful ping from a client to its default gateway rules out Layer 2 problems between them. Although the elimination process seems to be a rational, scientific procedure, you have to be aware that assumptions play a role in this process, too, and you have to be willing to go back and reexamine and verify your assumptions. If you do not, you might sometimes mistakenly eliminate the actual root cause of a problem as a nonprobable cause, and that means you will never be able to solve the problem.
After you have interpreted and analyzed the information that you have gathered, you start drawing conclusions from the results. On one hand, some of the discovered clues point toward certain issues that can be causing the problem, adding to your list of potential problem causes. For example, a very high CPU load on your multilayer switches can be a sign of a bridging loop. On the other hand, you might rule out some of the potential problem causes based on the gathered and analyzed facts. For example, a successful ping from a client to its default gateway rules out Layer 2 problems between them. Although the elimination process seems to be a rational, scientific procedure, you have to be aware that assumptions play a role in this process, too, and you have to be willing to go back and reexamine and verify your assumptions. If you do not, you might sometimes mistakenly eliminate the actual root cause of a problem as a nonprobable cause, and that means you will never be able to solve the problem.
An Example on Elimination and Assumptions
![]() You are examining a connectivity problem between a client and a server. As part of a follow-the-path troubleshooting approach, you decide to verify the Layer 2 connectivity between the client and the access switch to which it connects. You log on to the access switch and using the show interface command, you verify that the port connecting the client is up, input and output packets are recorded on the port, and that no errors are displayed in the packet statistics. Next, you verify that the client’s MAC address was correctly learned on the port according to the switch’s MAC address table using the show mac-address-table command. Therefore, you conclude that Layer 2 is operational between the client and the switch, and you continue your troubleshooting approach examining links further up the path.
You are examining a connectivity problem between a client and a server. As part of a follow-the-path troubleshooting approach, you decide to verify the Layer 2 connectivity between the client and the access switch to which it connects. You log on to the access switch and using the show interface command, you verify that the port connecting the client is up, input and output packets are recorded on the port, and that no errors are displayed in the packet statistics. Next, you verify that the client’s MAC address was correctly learned on the port according to the switch’s MAC address table using the show mac-address-table command. Therefore, you conclude that Layer 2 is operational between the client and the switch, and you continue your troubleshooting approach examining links further up the path.
![]() You must always keep in mind which of the assumptions you have made might need to be reexamined later. The first assumption made in this example is that the MAC address table entry and port statistics were current. Because this information might not be quite fresh, you might need to first clear the counters and the MAC address table and then verify that the counters are still increasing and that the MAC address is learned again. The second assumption is hidden in the conclusion: Layer 2 is operational, which implies that the client and the switch are sending and receiving frames to each other successfully in both directions. The only thing that you can really prove is that Layer 2 is operational from the client to the switch, because the switch has received frames from the client.
You must always keep in mind which of the assumptions you have made might need to be reexamined later. The first assumption made in this example is that the MAC address table entry and port statistics were current. Because this information might not be quite fresh, you might need to first clear the counters and the MAC address table and then verify that the counters are still increasing and that the MAC address is learned again. The second assumption is hidden in the conclusion: Layer 2 is operational, which implies that the client and the switch are sending and receiving frames to each other successfully in both directions. The only thing that you can really prove is that Layer 2 is operational from the client to the switch, because the switch has received frames from the client.
![]() The fact that the interface is up and that frames were recorded as being sent by the switch does not give you definitive proof that the client has correctly received those frames. So even though it is reasonable to assume that, if a link is operational on Layer 2 in one direction it will also be operational in the other direction, this is still an assumption that you might need to come back to later.
The fact that the interface is up and that frames were recorded as being sent by the switch does not give you definitive proof that the client has correctly received those frames. So even though it is reasonable to assume that, if a link is operational on Layer 2 in one direction it will also be operational in the other direction, this is still an assumption that you might need to come back to later.
![]() Spotting faulty assumptions is one of the tricky aspects of troubleshooting, because usually you are not consciously making those assumptions. Making assumptions is part of the normal thought process. One helpful way to uncover hidden assumptions is to explain your reasoning to one of your colleagues or peers. Because people think differently, a peer might be able to spot the hidden assumptions that you are making and help you uncover them.
Spotting faulty assumptions is one of the tricky aspects of troubleshooting, because usually you are not consciously making those assumptions. Making assumptions is part of the normal thought process. One helpful way to uncover hidden assumptions is to explain your reasoning to one of your colleagues or peers. Because people think differently, a peer might be able to spot the hidden assumptions that you are making and help you uncover them.
Solving the Problem
![]() After the process of proposing and eliminating some of the potential problem causes, you end up with a short list of remaining possible causes. Based on experience, you might even be able to assign a certain measure of probability to each of the remaining potential causes. If this list still has many different possible problem causes and none of them clearly stands out as the most likely cause, you might have to go back and gather more information first and eliminate more problem causes before you can propose a good hypothesis. After you have reduced the list of potential causes to just a few (ideally just one), select one of them as your problem hypothesis. Before you start to test your proposal, however, you have to reassess whether the proposed problem cause is within your area of responsibilities. In other words, if the issue that you just proposed as your hypothesis causes the problem, you have to determine whether it is your responsibility to solve it or you have to escalate it to some other person or department. Figure 2-8 shows the steps that you take to reach a hypothesis followed by escalating it to another group, or by testing your hypothesis.
After the process of proposing and eliminating some of the potential problem causes, you end up with a short list of remaining possible causes. Based on experience, you might even be able to assign a certain measure of probability to each of the remaining potential causes. If this list still has many different possible problem causes and none of them clearly stands out as the most likely cause, you might have to go back and gather more information first and eliminate more problem causes before you can propose a good hypothesis. After you have reduced the list of potential causes to just a few (ideally just one), select one of them as your problem hypothesis. Before you start to test your proposal, however, you have to reassess whether the proposed problem cause is within your area of responsibilities. In other words, if the issue that you just proposed as your hypothesis causes the problem, you have to determine whether it is your responsibility to solve it or you have to escalate it to some other person or department. Figure 2-8 shows the steps that you take to reach a hypothesis followed by escalating it to another group, or by testing your hypothesis.


![]() If you decide to escalate the problem, ask yourself if this ends your involvement in the process. Note that escalating the problem is not the same as solving the problem. You have to think about how long it will take the other party to solve the problem and how urgent is the problem to them. Users affected by the problem might not be able to afford to wait long for the other group to fix the problem. If you cannot solve the problem, but it is too urgent to wait for the problem to be solved through an escalation, you might need to come up with a workaround. A temporary fix alleviates the symptoms experienced by the user, even if it does not address the root cause of the problem.
If you decide to escalate the problem, ask yourself if this ends your involvement in the process. Note that escalating the problem is not the same as solving the problem. You have to think about how long it will take the other party to solve the problem and how urgent is the problem to them. Users affected by the problem might not be able to afford to wait long for the other group to fix the problem. If you cannot solve the problem, but it is too urgent to wait for the problem to be solved through an escalation, you might need to come up with a workaround. A temporary fix alleviates the symptoms experienced by the user, even if it does not address the root cause of the problem.
![]() After a hypothesis is proposed identifying the cause of a problem, the next step is to come up with a possible solution (or workaround) to that problem, and plan an implementation scheme. Usually, implementing a possible solution involves making changes to the network. Therefore, if your organization has defined procedures for regular network maintenance, you must follow your organization’s regular change procedures. The next step is to assess the impact of the change on the network and balance that against the urgency of the problem. If the urgency outweighs the impact and you decide to go ahead with the change, it is important to make sure that you have a way to revert to the original situation after you make the change. Even though you have determined that your hypothesis is the most likely cause of the problem and your solution is intended to fix it, you can never be entirely sure that your proposed solution will actually solve the problem. If the problem is not solved, you need to have a way to undo your changes and revert to the original situation. Upon creation of a rollback plan, you can implement your proposed solution according to your organization’s change procedures. Verify that the problem is solved and that the change you made did what you expected it to do. In other words, make sure the root cause of the problem and its symptoms are eliminated, and that your solution has not introduced any new problems. If all results are positive and desirable, you move on to the final stage of troubleshooting, which is integrating the solution and documenting your work. Figure 2-9 shows the flow of tasks while you implement and test your proposed hypothesis and either solve the problem or end up rolling back your changes.
After a hypothesis is proposed identifying the cause of a problem, the next step is to come up with a possible solution (or workaround) to that problem, and plan an implementation scheme. Usually, implementing a possible solution involves making changes to the network. Therefore, if your organization has defined procedures for regular network maintenance, you must follow your organization’s regular change procedures. The next step is to assess the impact of the change on the network and balance that against the urgency of the problem. If the urgency outweighs the impact and you decide to go ahead with the change, it is important to make sure that you have a way to revert to the original situation after you make the change. Even though you have determined that your hypothesis is the most likely cause of the problem and your solution is intended to fix it, you can never be entirely sure that your proposed solution will actually solve the problem. If the problem is not solved, you need to have a way to undo your changes and revert to the original situation. Upon creation of a rollback plan, you can implement your proposed solution according to your organization’s change procedures. Verify that the problem is solved and that the change you made did what you expected it to do. In other words, make sure the root cause of the problem and its symptoms are eliminated, and that your solution has not introduced any new problems. If all results are positive and desirable, you move on to the final stage of troubleshooting, which is integrating the solution and documenting your work. Figure 2-9 shows the flow of tasks while you implement and test your proposed hypothesis and either solve the problem or end up rolling back your changes.
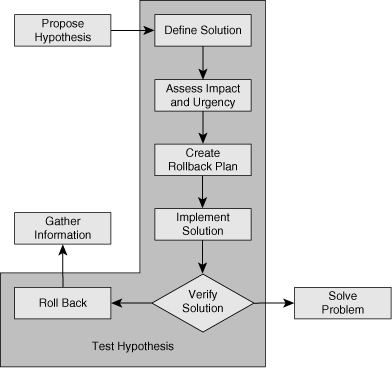
![]() You must have a plan for the situation if it turns out that the problem was not fixed, the symptoms have not disappeared, or new problems have been introduced by the change that you have made. In this case, you should execute your rollback plan, revert to the original situation, and resume the troubleshooting process. It is important to determine if the root cause hypothesis was invalid or whether it was simply the proposed solution that did not work.
You must have a plan for the situation if it turns out that the problem was not fixed, the symptoms have not disappeared, or new problems have been introduced by the change that you have made. In this case, you should execute your rollback plan, revert to the original situation, and resume the troubleshooting process. It is important to determine if the root cause hypothesis was invalid or whether it was simply the proposed solution that did not work.
![]() After you have confirmed your hypothesis and verified that the symptoms have disappeared, you have essentially solved the problem. All you need to do then is to make sure that the changes you made are integrated into the regular implementation of the network and that any maintenance procedures associated with those changes are executed. You will have to create backups of any changed configurations or upgraded software. You will have to document all changes to make sure that the network documentation still accurately describes the current state of the network. In addition, you must perform any other actions that are prescribed by your organization’s change control procedures. Figure 2-10 shows that upon receiving successful results from testing your hypothesis, you incorporate your solution and perform the final tasks such as backup, documentation, and communication, before you report the problem as solved.
After you have confirmed your hypothesis and verified that the symptoms have disappeared, you have essentially solved the problem. All you need to do then is to make sure that the changes you made are integrated into the regular implementation of the network and that any maintenance procedures associated with those changes are executed. You will have to create backups of any changed configurations or upgraded software. You will have to document all changes to make sure that the network documentation still accurately describes the current state of the network. In addition, you must perform any other actions that are prescribed by your organization’s change control procedures. Figure 2-10 shows that upon receiving successful results from testing your hypothesis, you incorporate your solution and perform the final tasks such as backup, documentation, and communication, before you report the problem as solved.
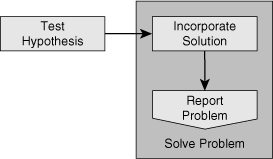
![]() The last thing you do is to communicate that the problem has been solved. At a minimum, you will have to communicate back to the original user that reported the problem, but if you have involved others as part of an escalation process, you should communicate with them, too. For any of the processes and procedures described here, each organization will have to make its own choices in how much of these procedures should be described, formalized, and followed. However, anyone involved in troubleshooting will benefit from reviewing these processes and comparing them to their own troubleshooting habits
The last thing you do is to communicate that the problem has been solved. At a minimum, you will have to communicate back to the original user that reported the problem, but if you have involved others as part of an escalation process, you should communicate with them, too. For any of the processes and procedures described here, each organization will have to make its own choices in how much of these procedures should be described, formalized, and followed. However, anyone involved in troubleshooting will benefit from reviewing these processes and comparing them to their own troubleshooting habits
Integrating Troubleshooting into the Network Maintenance Process
![]() Troubleshooting is a process that takes place as part of many different network maintenance tasks. For example, it might be necessary to troubleshoot issues arisen after implementation of new devices. Similarly, it could be necessary to troubleshoot after a network maintenance task such as a software upgrade. Consequently, troubleshooting processes should be integrated into network maintenance procedures and vice versa. When troubleshooting procedures and maintenance procedures are properly aligned, the overall network maintenance process will be more effective.
Troubleshooting is a process that takes place as part of many different network maintenance tasks. For example, it might be necessary to troubleshoot issues arisen after implementation of new devices. Similarly, it could be necessary to troubleshoot after a network maintenance task such as a software upgrade. Consequently, troubleshooting processes should be integrated into network maintenance procedures and vice versa. When troubleshooting procedures and maintenance procedures are properly aligned, the overall network maintenance process will be more effective.
Troubleshooting and Network Maintenance
![]() Network maintenance involves many different tasks, some of which are listed within Figure 2-11. For some of these tasks, such as supporting users, responding to network failures, or disaster recovery, troubleshooting is a major component of the tasks. Tasks that do not revolve around fault management, such as adding or replacing equipment, moving servers and users, and performing software upgrades, will regularly include troubleshooting processes, too. Hence, troubleshooting should not be seen as a standalone process, but as an essential skill that plays an important role in many different types of network maintenance tasks.
Network maintenance involves many different tasks, some of which are listed within Figure 2-11. For some of these tasks, such as supporting users, responding to network failures, or disaster recovery, troubleshooting is a major component of the tasks. Tasks that do not revolve around fault management, such as adding or replacing equipment, moving servers and users, and performing software upgrades, will regularly include troubleshooting processes, too. Hence, troubleshooting should not be seen as a standalone process, but as an essential skill that plays an important role in many different types of network maintenance tasks.


![]() To troubleshoot effectively, you must rely on many processes and resources that are part of the network maintenance process. You need to have access to up-to-date and accurate documentation. You rely on good backup and restore procedures to be able to roll back changes if they do not resolve the problem that you are troubleshooting. You need to have a good baseline of the network so that you know which conditions are supposed to be normal on your network and what kind of behavior is considered abnormal. Also, you need to have access to logs that are properly time stamped to find out when particular events have happened. So in many ways, the quality of your troubleshooting processes depends significantly on the quality of your network maintenance processes. Therefore, it makes sense to plan and implement troubleshooting activities as part of the overall network maintenance process and to make sure that troubleshooting processes and maintenance processes are aligned and support each other, making both processes more effective.
To troubleshoot effectively, you must rely on many processes and resources that are part of the network maintenance process. You need to have access to up-to-date and accurate documentation. You rely on good backup and restore procedures to be able to roll back changes if they do not resolve the problem that you are troubleshooting. You need to have a good baseline of the network so that you know which conditions are supposed to be normal on your network and what kind of behavior is considered abnormal. Also, you need to have access to logs that are properly time stamped to find out when particular events have happened. So in many ways, the quality of your troubleshooting processes depends significantly on the quality of your network maintenance processes. Therefore, it makes sense to plan and implement troubleshooting activities as part of the overall network maintenance process and to make sure that troubleshooting processes and maintenance processes are aligned and support each other, making both processes more effective.
Documentation
![]() Having accurate and current network documentation can tremendously increase the speed and effectiveness of troubleshooting processes. Having good network diagrams can especially help in quickly isolating problems to a particular part of the network, tracing the flow of traffic, and verifying connections between devices. Having a good IP address schematic and patching administration is invaluable, too, and can save a lot of time while trying to locate devices and IP addresses. Figure 2-12 shows some network documentation that is always valuable to have.
Having accurate and current network documentation can tremendously increase the speed and effectiveness of troubleshooting processes. Having good network diagrams can especially help in quickly isolating problems to a particular part of the network, tracing the flow of traffic, and verifying connections between devices. Having a good IP address schematic and patching administration is invaluable, too, and can save a lot of time while trying to locate devices and IP addresses. Figure 2-12 shows some network documentation that is always valuable to have.


![]() On the other hand, documentation that is wrong or outdated is often worse than having no documentation at all. If the documentation that you have is inaccurate or out-of-date, you might start working with information that is wrong and you might end up drawing the wrong conclusions and potentially lose a lot of time before you discover that the documentation is incorrect and cannot be relied upon.
On the other hand, documentation that is wrong or outdated is often worse than having no documentation at all. If the documentation that you have is inaccurate or out-of-date, you might start working with information that is wrong and you might end up drawing the wrong conclusions and potentially lose a lot of time before you discover that the documentation is incorrect and cannot be relied upon.
![]() Although everyone who is involved in network maintenance will agree that updating documentation is an essential part of network maintenance tasks, they will all recognize that in the heat of the moment, when you are troubleshooting a problem that is affecting network connectivity for many users, documenting the process and any changes that you are making is one of the last things on your mind. There are several ways to alleviate this problem. First, make sure that any changes you make during troubleshooting are handled in accordance with normal change procedures (if not during the troubleshooting process itself, then at least after the fact). You might loosen the requirements concerning authorization and scheduling of changes during major failures, but you have to make sure that after the problem has been solved or a workaround has been implemented to restore connectivity, you always go through any of the standard administrative processes like updating the documentation. Because you know that you will have to update the documentation afterward, there is an incentive to keep at least a minimal log of the changes that you make while troubleshooting.
Although everyone who is involved in network maintenance will agree that updating documentation is an essential part of network maintenance tasks, they will all recognize that in the heat of the moment, when you are troubleshooting a problem that is affecting network connectivity for many users, documenting the process and any changes that you are making is one of the last things on your mind. There are several ways to alleviate this problem. First, make sure that any changes you make during troubleshooting are handled in accordance with normal change procedures (if not during the troubleshooting process itself, then at least after the fact). You might loosen the requirements concerning authorization and scheduling of changes during major failures, but you have to make sure that after the problem has been solved or a workaround has been implemented to restore connectivity, you always go through any of the standard administrative processes like updating the documentation. Because you know that you will have to update the documentation afterward, there is an incentive to keep at least a minimal log of the changes that you make while troubleshooting.
![]() One good policy to keep your documentation accurate, assuming that people will forget to update the documentation, is to schedule regular checks of the documentation. However, verifying documentation manually is tedious work, so you will probably prefer to implement an automated system for that. For configuration changes, you could implement a system that downloads all device configurations on a regular basis and compares the configuration to the last version to spot any differences. There are also various IOS features such as the Configuration Archive, Rollback feature, and the Embedded Event Manager that can be leveraged to create automatic configuration backups, to log configuration commands to a syslog server, or to even send out configuration differences via e-mail.
One good policy to keep your documentation accurate, assuming that people will forget to update the documentation, is to schedule regular checks of the documentation. However, verifying documentation manually is tedious work, so you will probably prefer to implement an automated system for that. For configuration changes, you could implement a system that downloads all device configurations on a regular basis and compares the configuration to the last version to spot any differences. There are also various IOS features such as the Configuration Archive, Rollback feature, and the Embedded Event Manager that can be leveraged to create automatic configuration backups, to log configuration commands to a syslog server, or to even send out configuration differences via e-mail.
Creating a Baseline
![]() An essential troubleshooting technique is to compare what is happening on the network to what is expected or to what is normal on the network. Whenever you spot abnormal behavior in an area of the network that is experiencing problems, there is a good chance that it is related to the problems. It could be the cause of the problem, or it could be another symptom that might help point toward the underlying root cause. Either way, it is always worth investigating abnormal behavior to find out whether it is related to the problem. For example, suppose you are troubleshooting an application problem, and while you are following the path between the client and the server, you notice that one of the routers is also a bit slow in its responses to your commands. You execute the show processes cpu command and notice that the average CPU load over the past 5 seconds was 97 percent and over the last 1 minute was around 39 percent. You might wonder if this router’s high CPU utilization might be the cause of the problem you are troubleshooting. On one hand, this could be an important clue that is worth investigating, but on the other hand, it could be that your router regularly runs at 40 percent to 50 percent CPU and it is not related to this problem at all. In this case, you could potentially waste a lot of time trying to find the cause for the high CPU load, while it is entirely unrelated to the problem at hand.
An essential troubleshooting technique is to compare what is happening on the network to what is expected or to what is normal on the network. Whenever you spot abnormal behavior in an area of the network that is experiencing problems, there is a good chance that it is related to the problems. It could be the cause of the problem, or it could be another symptom that might help point toward the underlying root cause. Either way, it is always worth investigating abnormal behavior to find out whether it is related to the problem. For example, suppose you are troubleshooting an application problem, and while you are following the path between the client and the server, you notice that one of the routers is also a bit slow in its responses to your commands. You execute the show processes cpu command and notice that the average CPU load over the past 5 seconds was 97 percent and over the last 1 minute was around 39 percent. You might wonder if this router’s high CPU utilization might be the cause of the problem you are troubleshooting. On one hand, this could be an important clue that is worth investigating, but on the other hand, it could be that your router regularly runs at 40 percent to 50 percent CPU and it is not related to this problem at all. In this case, you could potentially waste a lot of time trying to find the cause for the high CPU load, while it is entirely unrelated to the problem at hand.
![]() The only way to know what is normal for your network is to measure the network’s behavior continuously. Knowing what to measure is different for each network. In general, the more you know, the better it is, but obviously this has to be balanced against the effort and cost involved in implementing and maintaining a performance management system. The following list describes some useful data to gather and create a baseline:
The only way to know what is normal for your network is to measure the network’s behavior continuously. Knowing what to measure is different for each network. In general, the more you know, the better it is, but obviously this has to be balanced against the effort and cost involved in implementing and maintaining a performance management system. The following list describes some useful data to gather and create a baseline:
- Basic performance statistics such as the interface load for critical network links and the CPU load and memory usage of routers and switches: These values can be polled and collected on a regular basis using SNMP and graphed for visual inspection.
- Accounting of network traffic: Remote Monitoring (RMON), Network Based Application Recognition (NBAR), or NetFlow statistics can be used to profile different types of traffic on the network.
- Measurements of network performance characteristics: The IP SLA feature in Cisco IOS can be used to measure critical performance indicators such as delay and jitter across the network infrastructure.
![]() These baseline measurements are useful for troubleshooting, but they are also useful inputs for capacity planning, network usage accounting, and SLA monitoring. Clearly, a synergy exists between gathering traffic and performance statistics as part of regular network maintenance and using those statistics as a baseline during troubleshooting. Moreover, once you have the infrastructure in place to collect, analyze, and graph network statistics, you can also leverage this infrastructure to troubleshoot specific performance problems. For example, if you notice that a router crashes once a week and you suspect a memory leak as the cause of this issue, you could decide to graph the router’s memory usage for a certain period of time to see whether you can find a correlation between the crashes and the memory usage.
These baseline measurements are useful for troubleshooting, but they are also useful inputs for capacity planning, network usage accounting, and SLA monitoring. Clearly, a synergy exists between gathering traffic and performance statistics as part of regular network maintenance and using those statistics as a baseline during troubleshooting. Moreover, once you have the infrastructure in place to collect, analyze, and graph network statistics, you can also leverage this infrastructure to troubleshoot specific performance problems. For example, if you notice that a router crashes once a week and you suspect a memory leak as the cause of this issue, you could decide to graph the router’s memory usage for a certain period of time to see whether you can find a correlation between the crashes and the memory usage.
Communication and Change Control
![]() Communication is an essential part of the troubleshooting process. To review, the main phases of structured troubleshooting are as follows:
Communication is an essential part of the troubleshooting process. To review, the main phases of structured troubleshooting are as follows:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]() Figure 2-13 shows several spots where, while performing structured troubleshooting, communication is necessary if not inevitable.
Figure 2-13 shows several spots where, while performing structured troubleshooting, communication is necessary if not inevitable.


![]() Within each phase of the troubleshooting process, communication plays a role:
Within each phase of the troubleshooting process, communication plays a role:
- Defining the problem: Even though this is the first step of the structured troubleshooting, it is triggered by the user reporting the problem. Reporting the problem and defining the problem are not the same. When someone reports a problem, it is often too vague to act on it immediately. You have to verify the problem and gather as much information as you can about the symptoms from the person who reported the problem. Asking good questions and carefully listening to the answers is essential in this phase. You might ask questions such as these: “What do you mean exactly when you say that something is failing? Did you make any changes before the problem started? Did you notice anything special before this problem started? When did it last work? Has it ever worked?” After you communicate with the users and perhaps see the problems for yourself, and so on, you make a precise and clear problem definition. Clearly, this step is all about communication.
- Gathering facts: During this phase of the process, you will often depend on other engineers or users to gather information for you. You might need to obtain information contained in server or application logs, configurations of devices that you do not manage, information about outages from a service provider, or information from users in different locations, to compare against the location that is experiencing the problem. Clearly, communicating what information you need and how that information can be obtained determines how successfully you can acquire the information you really need.
- Analyzing information and eliminate possibilities: In itself, interpretation and analysis is mostly a solitary process, but there are still some communication aspects to this phase. First of all, you cannot be experienced in every aspect of networking, so if you find that you are having trouble interpreting certain results or if you lack knowledge about certain processes, you can ask specialists on your team to help you out. Also, there is always a chance that you are misinterpreting results, misreading information, making wrong assumptions, or are having other flaws in your interpretation and analysis. A different viewpoint can often help in these situations, so discussing your reasoning and results with teammates to validate your assumptions and conclusions can be very helpful, especially when you are stuck.
- Proposing and testing a hypothesis: Most of the time, testing a hypothesis involves making changes to the network. These changes may be disruptive, and users may be impacted. Even if you have decided that the urgency of the problem outweighs the impact and the change will have to be made, you should still communicate clearly what you are doing and why you are doing it. Even if your changes will not have a major impact on the users or the business, you should still coordinate and communicate any changes that you are making. When other team members are working on the same problem, you have to make sure that you are not both making changes. Any results from the elimination process might be rendered invalid if a change was made during the information-gathering phase and you were not aware of it. Also, if two changes are made in quick succession and it turns out that the problem was resolved, you will not know which of the two changes actually fixed it. This does not mean that you cannot be working on the same problem as a team, but you have to adhere to certain rules. Having multiple people working on different parts of the network, gathering information in parallel or pursuing different strategies, can help in finding the cause faster. During a major disaster, when every minute counts, the extra speed that you can gain by working in parallel may prove valuable. However, any changes or other disruptive actions should be carefully coordinated and communicated.
- Solving the problem: Clearly, this phase also involves some communication. You must report back to the person who originally reported the problem that the problem has been solved. Also, you must communicate this to any other people who were involved during the process. Finally, you will have to go through any communication that is involved in the normal change processes, to make sure that the changes that you made are properly integrated in the standard network maintenance processes.
![]() Sometimes it is necessary to escalate the problem to another person or another group. Common reasons for this could be that you do not have sufficient knowledge and skills and you want to escalate the problem to a specialist or to a more senior engineer, or that you are working in shifts and you need to hand over the problem as your shift ends. Handing the troubleshooting task over to someone else does not only require clear communication of the results of your process, such as gathered information and conclusions that you have drawn, but it also includes any communication that has been going on up to this point. This is where an issue-tracking or trouble-ticketing system can be of tremendous value, especially if it integrates well with other means of communication such as e-mail.
Sometimes it is necessary to escalate the problem to another person or another group. Common reasons for this could be that you do not have sufficient knowledge and skills and you want to escalate the problem to a specialist or to a more senior engineer, or that you are working in shifts and you need to hand over the problem as your shift ends. Handing the troubleshooting task over to someone else does not only require clear communication of the results of your process, such as gathered information and conclusions that you have drawn, but it also includes any communication that has been going on up to this point. This is where an issue-tracking or trouble-ticketing system can be of tremendous value, especially if it integrates well with other means of communication such as e-mail.
![]() Finally, another communication process that requires some attention is how to communicate the progress of your troubleshooting process to the business (management or otherwise). When you are experiencing a major outage, there will usually be a barrage of questions from business managers and users such as “What are you doing to repair this issue? How long will it take before it is solved? Can you implement any workarounds? What do you need to fix this?” Although these are all reasonable questions, the truth is that many of these questions cannot be answered until the cause of the problem is found. At the same time, all the time spent communicating about the process is taken away from the actual troubleshooting effort itself. Therefore, it is worthwhile to streamline this process, for instance by having one of the senior team members act as a conduit for all communication. All questions are routed to this person, and any updates and changes are communicated to him; this person will then update the key stakeholders. This way, the engineers who are actually working on the problem can work with a minimal amount of distraction.
Finally, another communication process that requires some attention is how to communicate the progress of your troubleshooting process to the business (management or otherwise). When you are experiencing a major outage, there will usually be a barrage of questions from business managers and users such as “What are you doing to repair this issue? How long will it take before it is solved? Can you implement any workarounds? What do you need to fix this?” Although these are all reasonable questions, the truth is that many of these questions cannot be answered until the cause of the problem is found. At the same time, all the time spent communicating about the process is taken away from the actual troubleshooting effort itself. Therefore, it is worthwhile to streamline this process, for instance by having one of the senior team members act as a conduit for all communication. All questions are routed to this person, and any updates and changes are communicated to him; this person will then update the key stakeholders. This way, the engineers who are actually working on the problem can work with a minimal amount of distraction.
Change Control
![]() Change control is one of the most fundamental processes in network maintenance. By strictly controlling when changes are made, defining what type of authorization is required and what actions need to be taken as part of that process, you can reduce the frequency and duration of unplanned outages and thereby increase the overall uptime of your network. You must therefore understand how the changes made as part of troubleshooting fit into the overall change processes. Essentially, there is not anything different between making a change as part of the maintenance process or as part of troubleshooting. Most of the actions that you take are the same. You implement the change, verify that it achieved the desired results, roll back if it did not achieve the desired results, back up the changed configurations or software, and document/communicate your changes. The biggest difference between regular changes and emergency changes is the authorization required to make a change and the scheduling of the change. Within change-control procedures, there is always an aspect of balancing urgency, necessity, impact, and risk. The outcome of this assessment will determine whether a change can be executed immediately or if it will have to be scheduled at a later time.
Change control is one of the most fundamental processes in network maintenance. By strictly controlling when changes are made, defining what type of authorization is required and what actions need to be taken as part of that process, you can reduce the frequency and duration of unplanned outages and thereby increase the overall uptime of your network. You must therefore understand how the changes made as part of troubleshooting fit into the overall change processes. Essentially, there is not anything different between making a change as part of the maintenance process or as part of troubleshooting. Most of the actions that you take are the same. You implement the change, verify that it achieved the desired results, roll back if it did not achieve the desired results, back up the changed configurations or software, and document/communicate your changes. The biggest difference between regular changes and emergency changes is the authorization required to make a change and the scheduling of the change. Within change-control procedures, there is always an aspect of balancing urgency, necessity, impact, and risk. The outcome of this assessment will determine whether a change can be executed immediately or if it will have to be scheduled at a later time.
![]() The troubleshooting process can benefit tremendously from having well-defined and well-documented change processes. It is uncommon for devices or links just to fail from one moment to the next. In many cases, problems are triggered or caused by some sort of change. This can be a simple change, such as changing a cable or reconfiguring a setting, but it may also be more subtle, like a change in traffic patterns due to the outbreak of a new worm or virus. A problem can also be caused by a combination of changes, where the first change is the root cause of the problem, but the problem is not triggered until you make another change. For example, imagine a situation where somebody accidentally erases the router software from its flash. This will not cause the router to fail immediately, because it is running IOS from its RAM. However, if that router reboots because of a short power failure a month later, it will not boot, because it is missing the IOS in its flash memory. In this example, the root cause of the failure is the erased software, but the trigger is the power failure. This type of problem is harder to catch, and only in tightly controlled environments will you be able to find the root cause or prevent this type of problem. In the previous example, a log of all privileged EXEC commands executed on this router can reveal that the software had been erased at a previous date. You can conclude that one of the useful questions you can ask during fact gathering is “Has anything been changed?” The answer to this question can very likely be found in the network documentation or change logs if network policies enforce rigid documentation and change-control procedures.
The troubleshooting process can benefit tremendously from having well-defined and well-documented change processes. It is uncommon for devices or links just to fail from one moment to the next. In many cases, problems are triggered or caused by some sort of change. This can be a simple change, such as changing a cable or reconfiguring a setting, but it may also be more subtle, like a change in traffic patterns due to the outbreak of a new worm or virus. A problem can also be caused by a combination of changes, where the first change is the root cause of the problem, but the problem is not triggered until you make another change. For example, imagine a situation where somebody accidentally erases the router software from its flash. This will not cause the router to fail immediately, because it is running IOS from its RAM. However, if that router reboots because of a short power failure a month later, it will not boot, because it is missing the IOS in its flash memory. In this example, the root cause of the failure is the erased software, but the trigger is the power failure. This type of problem is harder to catch, and only in tightly controlled environments will you be able to find the root cause or prevent this type of problem. In the previous example, a log of all privileged EXEC commands executed on this router can reveal that the software had been erased at a previous date. You can conclude that one of the useful questions you can ask during fact gathering is “Has anything been changed?” The answer to this question can very likely be found in the network documentation or change logs if network policies enforce rigid documentation and change-control procedures.
Summary
![]() The fundamental elements of a troubleshooting process are as following:
The fundamental elements of a troubleshooting process are as following:
- Gathering of information and symptoms
- Analyzing information
- Eliminating possible causes
- Formulating a hypothesis
- Testing the hypothesis
![]() Some commonly used troubleshooting approaches are as follows:
Some commonly used troubleshooting approaches are as follows:
- Top down
- Bottom up
- Divide and conquer
- Follow the path
- Spot the differences
- Move the problem
![]() A structured approach to troubleshooting (no matter what the exact method is) will yield more predictable results in the long run and will make it easier to pick up the process where you left off in a later stage or to hand it over to someone else.
A structured approach to troubleshooting (no matter what the exact method is) will yield more predictable results in the long run and will make it easier to pick up the process where you left off in a later stage or to hand it over to someone else.
![]() The structured troubleshooting begins with problem definition followed by fact gathering. The gathered information, network documentation, baseline information, plus your research results and past experience are all used as input while you interpret and analyze the gathered information to eliminate possibilities and identify the source of the problem. Based on your continuous information analysis and the assumptions you make, you eliminate possible problem causes from the pool of proposed causes until you have a final proposal that takes you to the next step of the troubleshooting process: formulating and proposing a hypothesis. Based on your hypothesis, the problem might or might not fall within your area of responsibility, so proposing a hypothesis is either followed by escalating it to another group or by testing your hypothesis. If your test results are positive, you have to plan and implement a solution. The solution entails changes that must follow the change-control procedures within your organization. The results and all the changes you make must be clearly documented and communicated with all the relevant parties.
The structured troubleshooting begins with problem definition followed by fact gathering. The gathered information, network documentation, baseline information, plus your research results and past experience are all used as input while you interpret and analyze the gathered information to eliminate possibilities and identify the source of the problem. Based on your continuous information analysis and the assumptions you make, you eliminate possible problem causes from the pool of proposed causes until you have a final proposal that takes you to the next step of the troubleshooting process: formulating and proposing a hypothesis. Based on your hypothesis, the problem might or might not fall within your area of responsibility, so proposing a hypothesis is either followed by escalating it to another group or by testing your hypothesis. If your test results are positive, you have to plan and implement a solution. The solution entails changes that must follow the change-control procedures within your organization. The results and all the changes you make must be clearly documented and communicated with all the relevant parties.
![]() Having accurate and current network documentation can tremendously increase the speed and effectiveness of troubleshooting processes. Documentation that is wrong or outdated is often worse than having no documentation at all.
Having accurate and current network documentation can tremendously increase the speed and effectiveness of troubleshooting processes. Documentation that is wrong or outdated is often worse than having no documentation at all.
![]() To gather and create a network baseline, the following data proves useful:
To gather and create a network baseline, the following data proves useful:
- Basic performance statistics obtain by running show commands
- Accounting of network traffic using RMON, NBAR, or NetFlow statistics
- Measurements of network performance characteristics using the IP SLA feature in IOS
![]() Communication is an essential part of the troubleshooting process, and it happens in all of the following stages of troubleshooting:
Communication is an essential part of the troubleshooting process, and it happens in all of the following stages of troubleshooting:
- Reporting the problem
- Gathering information
- Proposing and testing a hypothesis
- Solving the problem
![]() Change control is one of the most fundamental processes in network maintenance. By strictly controlling when changes are made, defining what type of authorization is required and what actions need to be taken as part of that process, you can reduce the frequency and duration of unplanned outages and thereby increase the overall uptime of your network. Essentially, there is not much difference between making a change as part of the maintenance process or as part of troubleshooting.
Change control is one of the most fundamental processes in network maintenance. By strictly controlling when changes are made, defining what type of authorization is required and what actions need to be taken as part of that process, you can reduce the frequency and duration of unplanned outages and thereby increase the overall uptime of your network. Essentially, there is not much difference between making a change as part of the maintenance process or as part of troubleshooting.
0 comments
Post a Comment