
Routing Protocols for the Enterprise
![]() Routing protocols vary in their support for many features, including VLSM, summarization, scalability, and fast convergence. There is no best protocol—the choice depends on many factors. This section discusses the most common routing protocols for use within the enterprise and evaluates their suitability for given network requirements.
Routing protocols vary in their support for many features, including VLSM, summarization, scalability, and fast convergence. There is no best protocol—the choice depends on many factors. This section discusses the most common routing protocols for use within the enterprise and evaluates their suitability for given network requirements.
![]() First, the interior routing protocols EIGRP, OSPF, and Integrated IS-IS are discussed, followed by a description of BGP.
First, the interior routing protocols EIGRP, OSPF, and Integrated IS-IS are discussed, followed by a description of BGP.
| Note |
|
 EIGRP
EIGRP
![]() EIGRP is a Cisco-proprietary protocol for routing IPv4; EIGRP can also be configured for routing IP version 6 (IPv6), Internetwork Packet Exchange (IPX), and AppleTalk traffic. EIGRP is an enhanced version of IGRP, which is a pure distance vector protocol. EIGRP, however, is a hybrid routing protocol—it is a distance vector protocol with additional link-state protocol features. EIGRP features include the following:
EIGRP is a Cisco-proprietary protocol for routing IPv4; EIGRP can also be configured for routing IP version 6 (IPv6), Internetwork Packet Exchange (IPX), and AppleTalk traffic. EIGRP is an enhanced version of IGRP, which is a pure distance vector protocol. EIGRP, however, is a hybrid routing protocol—it is a distance vector protocol with additional link-state protocol features. EIGRP features include the following:
- Uses triggered updates (EIGRP has no periodic updates).
- Uses a topology table to keep all routes received from its neighbors, not only the best routes.
- Establishes adjacencies with neighboring routers using the Hello protocol.
- Uses multicast, rather than broadcast, for communication.
- Supports VLSM.
- Supports manual route summarization. EIGRP summarizes on major network boundaries by default, but this feature can be turned off, and summarization can be configured at any point in the network.
- Can be used to create hierarchically structured, large networks.
- Supports unequal-cost load balancing.
![]() Routes are propagated in EIGRP in a distance vector manner, from neighbor to neighbor, and only the best routes are sent onward. A router that runs EIGRP does not have a complete view of a network because it sees only the routes it receives from its neighbors. In contrast, with a pure link-state protocol (OSPF and IS-IS), all routers in the same area have identical information and therefore have a complete view of the area and its link states.
Routes are propagated in EIGRP in a distance vector manner, from neighbor to neighbor, and only the best routes are sent onward. A router that runs EIGRP does not have a complete view of a network because it sees only the routes it receives from its neighbors. In contrast, with a pure link-state protocol (OSPF and IS-IS), all routers in the same area have identical information and therefore have a complete view of the area and its link states.
![]() Recall that the default EIGRP metric calculation uses the minimum bandwidth and cumulative delay of the path. Other parameters can also be used in this calculation, including worst reliability between source and destination and worst loading on a link between source and destination. Note that the maximum transmission unit and hop count are carried in the EIGRP routing updates but are not used in the metric calculation.
Recall that the default EIGRP metric calculation uses the minimum bandwidth and cumulative delay of the path. Other parameters can also be used in this calculation, including worst reliability between source and destination and worst loading on a link between source and destination. Note that the maximum transmission unit and hop count are carried in the EIGRP routing updates but are not used in the metric calculation.
EIGRP Terminology
![]() Some EIGRP-related terms include the following:
Some EIGRP-related terms include the following:
- Neighbor table: EIGRP routers use hello packets to discover neighbors. When a router discovers and forms an adjacency with a new neighbor, it includes the neighbor’s address and the interface through which it can be reached in an entry in the neighbor table. This table is comparable to OSPF’s neighbor table (adjacency database); it serves the same purpose, which is to ensure bidirectional communication between each of the directly connected neighbors. EIGRP keeps a neighbor table for each supported network protocol.
- Topology table: When a router dynamically discovers a new neighbor, it sends an update about the routes it knows to its new neighbor and receives the same from the new neighbor. These updates populate the topology table. The topology table contains all destinations advertised by neighboring routers; in other words, each router stores its neighbors’ routing tables in its EIGRP topology table. If a neighbor is advertising a destination, it must be using that route to forward packets; this rule must be strictly followed by all distance vector protocols. An EIGRP router maintains a topology table for each network protocol configured.
- Advertised distance (AD) and feasible distance (FD): EIGRP uses the Diffusing Update Algorithm (DUAL). DUAL uses distance information, known as a metric or cost, to select efficient loop-free paths. The lowest-cost route is calculated by adding the cost between the next-hop router and the destination—referred to as the advertised distance—to the cost between the local router and the next-hop router. The sum of these costs is referred to as the feasible distance.
- Successor: A successor, also called a current successor, is a neighboring router that has a least-cost path to a destination (the lowest FD) guaranteed not to be part of a routing loop. Successors are offered to the routing table to be used to forward packets. Multiple successors can exist if they have the same FD.
- Routing table: The routing table holds the best routes to each destination and is used to forward packets. Successor routes are offered to the routing table. The router maintains one routing table for each network protocol.
- Feasible successor: Along with keeping least-cost paths, DUAL keeps backup paths to each destination. The next-hop router for a backup path is called the feasible successor. To qualify as a feasible successor, a next-hop router must have an AD less than the FD of the current successor route. In other words, a feasible successor is a neighbor that is closer to the destination, but is not in the least-cost path and, therefore, is not used to forward data. Feasible successors are selected at the same time as successors but are kept only in the topology table. The topology table can maintain multiple feasible successors for a destination.
![]() If the route via the successor becomes invalid because of a topology change or if a neighbor changes the metric, DUAL checks for feasible successors to the destination. If a feasible successor is found, DUAL uses it, thereby avoiding a recomputation of the route. If no suitable feasible successor exists, a recomputation must occur to determine the new successor. Although recomputation is not processor-intensive, it affects convergence time, so it is advantageous to avoid unnecessary recomputations.
If the route via the successor becomes invalid because of a topology change or if a neighbor changes the metric, DUAL checks for feasible successors to the destination. If a feasible successor is found, DUAL uses it, thereby avoiding a recomputation of the route. If no suitable feasible successor exists, a recomputation must occur to determine the new successor. Although recomputation is not processor-intensive, it affects convergence time, so it is advantageous to avoid unnecessary recomputations.
EIGRP Characteristics
![]() The characteristics that make EIGRP suitable for deployment in enterprise networks include the following:
The characteristics that make EIGRP suitable for deployment in enterprise networks include the following:
- Fast convergence: One advantage of EIGRP is its fast-converging DUAL route calculation mechanism. This mechanism allows backup routes (the feasible successors) to be kept in the topology table for use if the primary route fails. Because this process occurs locally on the router, the switchover to a backup route (if one exists) is immediate and does not involve action in any other routers.
- Improved scalability: Along with fast convergence, the ability to manually summarize also improves scalability. EIGRP summarizes routes on classful network boundaries by default. Automatic summarization can be turned off, and manual summarization can be configured at any point in the network, improving scalability and network performance because the routing protocol uses fewer resources.
- Use of VLSM: Because EIGRP is a classless routing protocol, it sends subnet mask information in its routing updates and therefore supports VLSM.
- Reduced bandwidth usage: Because EIGRP does not send periodic routing updates as other distance vector protocols do, it uses less bandwidth—particularly in large networks that have a large number of routes. On the other hand, EIGRP uses the Hello protocol to establish and maintain adjacencies with its neighbors. If many neighbors are reachable over the same physical link, as might be the case in NBMA networks, the Hello protocol might create significant routing traffic overhead. Therefore, the network must be designed appropriately to take advantage of EIGRP’s benefits.
- Multiple network layer protocol support: EIGRP supports multiple network layer protocols through Protocol-Dependent Modules (PDM). PDMs include support for IPv4, IPv6, IPX, and AppleTalk.
| Note |
|
OSPF
![]() OSPF is a standardized protocol for routing IPv4, developed in 1988 by the Internet Engineering Task Force to replace RIP in larger, more diverse media networks. In 1998, minor changes in OSPF version 2 (OSPFv2) addressed some of OSPF version 1’s problems while maintaining full backward compatibility.
OSPF is a standardized protocol for routing IPv4, developed in 1988 by the Internet Engineering Task Force to replace RIP in larger, more diverse media networks. In 1998, minor changes in OSPF version 2 (OSPFv2) addressed some of OSPF version 1’s problems while maintaining full backward compatibility.
| Note |
|
![]() OSPF was developed for use in large scalable networks in which RIP’s inherent limitations failed to satisfy requirements. OSPF is superior to RIP in all aspects, including the following:
OSPF was developed for use in large scalable networks in which RIP’s inherent limitations failed to satisfy requirements. OSPF is superior to RIP in all aspects, including the following:
- It converges much faster.
- It supports VLSM, manual summarization, and hierarchical structures.
- It has improved metric calculation for best path selection.
- It does not have hop-count limitations.
![]() At its inception, OSPF supported the largest networks.
At its inception, OSPF supported the largest networks.
OSPF Hierarchical Design
![]() Although OSPF was developed for large networks, its implementation requires proper design and planning; this is especially important for networks with 50 or more routers. The concept of multiple separate areas inside one domain (or AS) was implemented in OSPF to reduce the amount of routing traffic and make networks more scalable.
Although OSPF was developed for large networks, its implementation requires proper design and planning; this is especially important for networks with 50 or more routers. The concept of multiple separate areas inside one domain (or AS) was implemented in OSPF to reduce the amount of routing traffic and make networks more scalable.
![]() In OSPF, there must always be one backbone area—area 0—to which all other nonbackbone areas must be directly attached. A router is a member of an OSPF area when at least one of its interfaces operates in that area. Routers that reside on boundaries between the backbone and a nonbackbone area are called Area Border Routers (ABR) and have at least one interface in each area. The boundary between the areas is within the ABR itself.
In OSPF, there must always be one backbone area—area 0—to which all other nonbackbone areas must be directly attached. A router is a member of an OSPF area when at least one of its interfaces operates in that area. Routers that reside on boundaries between the backbone and a nonbackbone area are called Area Border Routers (ABR) and have at least one interface in each area. The boundary between the areas is within the ABR itself.
![]() If external routes are propagated into the OSPF AS, the router that redistributes those routes is called an Autonomous System Boundary Router (ASBR). Careful design and correct mapping of areas to the network topology are important because manual summarization of routes can only be performed on ABRs and ASBRs.
If external routes are propagated into the OSPF AS, the router that redistributes those routes is called an Autonomous System Boundary Router (ASBR). Careful design and correct mapping of areas to the network topology are important because manual summarization of routes can only be performed on ABRs and ASBRs.
![]() Traffic sent from one nonbackbone area to another always crosses the backbone. For example, in Figure 7-10, the Area 1 ABR must forward traffic from Area 1 destined for Area 2 into the backbone. The Area 2 ABR receives the traffic from the backbone and forwards it to the appropriate destination inside Area 2.
Traffic sent from one nonbackbone area to another always crosses the backbone. For example, in Figure 7-10, the Area 1 ABR must forward traffic from Area 1 destined for Area 2 into the backbone. The Area 2 ABR receives the traffic from the backbone and forwards it to the appropriate destination inside Area 2.


| Note |
|
OSPF Characteristics
![]() OSPF is a link-state protocol that has the following characteristics for deployment in enterprise networks:
OSPF is a link-state protocol that has the following characteristics for deployment in enterprise networks:
- Fast convergence: OSPF achieves fast convergence times using triggered link-state updates that include one or more link-state advertisements (LSA). LSAs describe the state of links on specific routers and are propagated unchanged within an area. Therefore, all routers in the same area have identical topology tables; each router has a complete view of all links and devices in the area. Depending on their type, LSAs are usually changed by ABRs when they cross into another area.When the OSPF topology table is fully populated, the SPF algorithm calculates the shortest paths to the destination networks. Triggered updates and metric calculation based on the cost of a specific link ensure quick selection of the shortest path toward the destination.By default, the OSPF link cost value is inversely proportional to the link’s bandwidth.
Note By default, the cost in Cisco routers is calculated using the formula 100 Mbps / bandwidth in Mbps. For example, a 64-kbps link has a cost of 1562, and a T1 link has a cost of 64. However, this formula is based on a maximum bandwidth of 100 Mbps, which results in a cost of 1. If the network includes faster links, the cost formula can be recalibrated. - Very good scalability: OSPF’s multiple area structure provides good scalability. However, OSPF’s strict area implementation rules require proper design to support other scalability features such as manual summarization of routes on ABRs and ASBRs, stub areas, totally stubby areas, and not-so-stubby areas (NSSA). The stub, totally stubby, and NSSA features for nonbackbone areas decrease the amount of LSA traffic from the backbone (area 0) into nonbackbone areas (and they are described further in the following sidebar). This allows lowend routers to run in the network’s peripheral areas, because fewer LSAs mean smaller OSPF topology tables, less OSPF memory usage, and lower CPU usage in stub area routers.
- Reduced bandwidth usage: Along with the area structure, the use of triggered (not periodic) updates and manual summarization reduces the bandwidth used by OSPF by limiting the volume of link-state update propagation. Recall, though, that OSPF does send updates every 30 minutes.
- VLSM support: Because OSPF is a classless routing protocol, it supports VLSM to achieve better use of IP address space.
![]() A variety of possible area types exist. The most commonly used are as follows:
A variety of possible area types exist. The most commonly used are as follows:
- Standard area: This default area accepts link updates, route summaries, and external routes.
- Backbone area (transit area): The backbone area, area 0, is the central entity to which all other areas connect to exchange and route information. The OSPF backbone has all the properties of a standard OSPF area.
- Stub area: This area does not accept information about routes external to the autonomous system, such as routes from non-OSPF sources. If routers need to route to networks outside the autonomous system, they use a default route, indicated as 0.0.0.0. Stub areas cannot contain ASBRs (except that the ABRs may also be ASBRs). Using a stub area reduces the size of the routing tables inside the area.
- Totally stubby area: A totally stubby area is a Cisco-specific feature that further reduces the number of routes in the routing tables inside the area. This area does not accept external autonomous system routes or summary routes from other areas internal to the autonomous system. If a router has to send a packet to a network external to the area, it sends the packet using a default route. Totally stubby areas cannot contain ASBRs (except that the ABRs may also be ASBRs).
- NSSA: This area offers benefits similar to those of a stub area. However, NSSAs allow ASBRs, which is against the rules in a stub area. A totally stubby NSSA (although it sounds like a very strange name) is a Cisco-specific feature that further reduces the size of the routing tables inside the NSSA.
Integrated IS-IS
![]() IS-IS was developed by Digital Equipment Corporation (DEC) as the dynamic link-state routing protocol for the Open Systems Interconnection (OSI) protocol suite. The OSI suite uses Connectionless Network Service (CLNS) to provide connectionless delivery of data, and the actual Layer 3 protocol is Connectionless Network Protocol (CLNP). CLNP is the OSI suite solution for connectionless delivery of data, similar to IP in the TCP/IP suite. IS-IS uses CLNS addresses to identify the routers and build the LSDB.
IS-IS was developed by Digital Equipment Corporation (DEC) as the dynamic link-state routing protocol for the Open Systems Interconnection (OSI) protocol suite. The OSI suite uses Connectionless Network Service (CLNS) to provide connectionless delivery of data, and the actual Layer 3 protocol is Connectionless Network Protocol (CLNP). CLNP is the OSI suite solution for connectionless delivery of data, similar to IP in the TCP/IP suite. IS-IS uses CLNS addresses to identify the routers and build the LSDB.
![]() IS-IS was adapted to the IP environment because IP is used on the Internet; this extended version of IS-IS for mixed OSI and IPv4 environments is called Integrated IS-IS. Integrated IS-IS tags CLNP routes with information on IP networks and subnets.
IS-IS was adapted to the IP environment because IP is used on the Internet; this extended version of IS-IS for mixed OSI and IPv4 environments is called Integrated IS-IS. Integrated IS-IS tags CLNP routes with information on IP networks and subnets.
| Note |
|
![]() Even if Integrated IS-IS is used only for routing IP (and not CLNP), OSI protocols are used to form the neighbor relationships between the routers; therefore, for Integrated ISIS to work, CLNS addresses must still be assigned to areas. This proves to be a major disadvantage when implementing Integrated IS-IS, because OSI and CLNS knowledge is not widespread in the enterprise networking community. Therefore, Integrated IS-IS is not recommended as an enterprise routing protocol; it is included here for completeness.
Even if Integrated IS-IS is used only for routing IP (and not CLNP), OSI protocols are used to form the neighbor relationships between the routers; therefore, for Integrated ISIS to work, CLNS addresses must still be assigned to areas. This proves to be a major disadvantage when implementing Integrated IS-IS, because OSI and CLNS knowledge is not widespread in the enterprise networking community. Therefore, Integrated IS-IS is not recommended as an enterprise routing protocol; it is included here for completeness.
Integrated IS-IS Terminology
![]() ISO specifications call routers intermediate systems. Thus, IS-IS is a router-to-router protocol, allowing routers to communicate with other routers.
ISO specifications call routers intermediate systems. Thus, IS-IS is a router-to-router protocol, allowing routers to communicate with other routers.
![]() IS-IS routing takes place at two levels within an AS: Level 1 (L1) and Level 2 (L2). L1 routing occurs within an IS-IS area and is responsible for routing inside an area. All devices in an L1 routing area have the same area address. Routing within an area is accomplished by looking at the locally significant address portion, known as the system ID, and choosing the lowest-cost path.
IS-IS routing takes place at two levels within an AS: Level 1 (L1) and Level 2 (L2). L1 routing occurs within an IS-IS area and is responsible for routing inside an area. All devices in an L1 routing area have the same area address. Routing within an area is accomplished by looking at the locally significant address portion, known as the system ID, and choosing the lowest-cost path.
![]() L2 routing occurs between IS-IS areas. L2 routers learn the locations of L1 routing areas and build an interarea routing table. L2 routers use the destination area address to route traffic using the lowest-cost path. Therefore, IS-IS supports two routing levels:
L2 routing occurs between IS-IS areas. L2 routers learn the locations of L1 routing areas and build an interarea routing table. L2 routers use the destination area address to route traffic using the lowest-cost path. Therefore, IS-IS supports two routing levels:
- L1 builds a common topology of system IDs in the local area and routes traffic within the area using the lowest-cost path.
- L2 exchanges prefix information (area addresses) between areas and routes traffic to an area using the lowest-cost path.
![]() To support the two routing levels, IS-IS defines three types of routers:
To support the two routing levels, IS-IS defines three types of routers:
- L1 routers use link-state packets (LSP) to learn about paths within the areas to which they connect (intra-area).
- L2 routers use LSPs to learn about paths among areas (interarea).
- Level 1/Level 2 (L1/L2) routers learn about paths both within and between areas. L1/L2 routers are equivalent to ABRs in OSPF.
![]() The three types of IS-IS routers are shown in Figure 7-11.
The three types of IS-IS routers are shown in Figure 7-11.


![]() The path of connected L2 and L1/L2 routers is called the backbone. All areas and the backbone must be contiguous.
The path of connected L2 and L1/L2 routers is called the backbone. All areas and the backbone must be contiguous.
![]() IS-IS area boundaries fall on the links, not within the routers. Each IS-IS router belongs to exactly one area. Neighboring routers learn that they are in the same or different areas and negotiate appropriate adjacencies—L1, L2, or both.
IS-IS area boundaries fall on the links, not within the routers. Each IS-IS router belongs to exactly one area. Neighboring routers learn that they are in the same or different areas and negotiate appropriate adjacencies—L1, L2, or both.
![]() Changing Level 1 routers into Level 1/Level 2 or Level 2 routers can easily expand the Integrated IS-IS backbone. In comparison, in OSPF, entire areas must be renumbered to achieve this.
Changing Level 1 routers into Level 1/Level 2 or Level 2 routers can easily expand the Integrated IS-IS backbone. In comparison, in OSPF, entire areas must be renumbered to achieve this.
Integrated IS-IS Characteristics
![]() IS-IS is a popular IP routing protocol in the ISP industry. The simplicity and stability of IS-IS make it robust in large internetworks. Integrated IS-IS characteristics include the following:
IS-IS is a popular IP routing protocol in the ISP industry. The simplicity and stability of IS-IS make it robust in large internetworks. Integrated IS-IS characteristics include the following:
- VLSM support: As a classless routing protocol, Integrated IS-IS supports VLSM.
- Fast convergence: Similar to OSPF, Integrated IS-IS owes its fast convergence characteristics to its link-state operation (including flooding of triggered link-state updates). Another feature that guarantees fast convergence and less CPU usage is the partial route calculation (PRC). Although Integrated IS-IS uses the same algorithm as OSPF for best path calculation, the full SPF calculation is initially performed on network startup only. When IP subnet information changes, only a PRC for the subnet in question runs on routers. This saves router resources and enables faster calculation. A full SPF calculation must be run for each OSPF change.
Note Introduced in Cisco IOS Release 12.0(24)S, the OSPF incremental SPF feature is more efficient than the full SPF algorithm and allows OSPF to converge on a new routing topology more quickly. Information on this feature is available in OSPF Incremental SPF, at http://www.cisco.com/en/US/products/ps6350/products_configuration_guide_chapter09186a00804556a5.html. - Excellent scalability: Integrated IS-IS is more scalable and flexible than OSPF; IS-IS backbone area design is not as strict as OSPF, thereby allowing for easy backbone extension.
- Reduced bandwidth usage: Triggered updates and the absence of periodic updates ensure that less bandwidth is used for routing information.
![]() Integrated IS-IS offers inherent support for LAN and point-to-point environments only, whereas NBMA point-to-multipoint environment support is not included. In NBMA environments, point-to-point links (subinterfaces) must be established for correct Integrated IS-IS operation.
Integrated IS-IS offers inherent support for LAN and point-to-point environments only, whereas NBMA point-to-multipoint environment support is not included. In NBMA environments, point-to-point links (subinterfaces) must be established for correct Integrated IS-IS operation.
![]() As mentioned, one disadvantage of Integrated IS-IS is its close association with the OSI world. Because few network administrators have adequate knowledge of OSI addressing and operation, implementation of Integrated IS-IS might be difficult.
As mentioned, one disadvantage of Integrated IS-IS is its close association with the OSI world. Because few network administrators have adequate knowledge of OSI addressing and operation, implementation of Integrated IS-IS might be difficult.
Summary of Interior Routing Protocol Features
![]() There is no best or worst routing protocol. The decision about which routing protocol to implement (or whether multiple routing protocols should indeed be implemented in a network) can be made only after you carefully consider the design goals and examine the network’s physical topology in detail.
There is no best or worst routing protocol. The decision about which routing protocol to implement (or whether multiple routing protocols should indeed be implemented in a network) can be made only after you carefully consider the design goals and examine the network’s physical topology in detail.
![]() Table 7-2 summarizes some characteristics of IP routing protocols discussed in this chapter. Although they are no longer recommended enterprise protocols, RIPv1, RIPv2, and IGRP are also included in this table for completeness.
Table 7-2 summarizes some characteristics of IP routing protocols discussed in this chapter. Although they are no longer recommended enterprise protocols, RIPv1, RIPv2, and IGRP are also included in this table for completeness.
Selecting an Appropriate Interior Routing Protocol
![]() The selection of a routing protocol is based on the design goals and the physical topology of the network. Both EIGRP and OSPF are recommended as enterprise routing protocols.
The selection of a routing protocol is based on the design goals and the physical topology of the network. Both EIGRP and OSPF are recommended as enterprise routing protocols.
![]() When choosing routing protocols, you can use Table 7-3 as a decision table template. Decision tables are discussed in Chapter 2, “Applying a Methodology to Network Design.” Additional rows can be added to specify other parameters that might be important in the specific network.
When choosing routing protocols, you can use Table 7-3 as a decision table template. Decision tables are discussed in Chapter 2, “Applying a Methodology to Network Design.” Additional rows can be added to specify other parameters that might be important in the specific network.
|
|
|
| |
|---|---|---|---|
|
|
|
| |
|
|
|
| |
|
|
|
| |
|
|
|
| |
|
|
|
| |
|
|
|
|
When to Choose EIGRP
![]() EIGRP is a Cisco-proprietary hybrid protocol that incorporates the best aspects of distance vector and link-state features. EIGRP keeps a topology table, it does not perform periodic route updates, and it does perform triggered updates. It is well suited to almost all environments, including LAN, point-to-point, and NBMA. The EIGRP split-horizon functionality can be disabled in NBMA environments. EIGRP is not suitable for dialup environments because it must maintain its neighbor relationships using periodic hello packets; sending these packets would mean that the dialup connections would have to stay up all the time.
EIGRP is a Cisco-proprietary hybrid protocol that incorporates the best aspects of distance vector and link-state features. EIGRP keeps a topology table, it does not perform periodic route updates, and it does perform triggered updates. It is well suited to almost all environments, including LAN, point-to-point, and NBMA. The EIGRP split-horizon functionality can be disabled in NBMA environments. EIGRP is not suitable for dialup environments because it must maintain its neighbor relationships using periodic hello packets; sending these packets would mean that the dialup connections would have to stay up all the time.
When to Choose OSPF
![]() OSPF is a standards-based link-state protocol that is based on the SPF algorithm for best path calculation. OSPF was initially designed for networks of point-to-point links and was later adapted for operation in LAN and NBMA environments. OSPF can be used on dialup links with the OSPF Demand Circuit feature, which suppresses the Hello protocol.
OSPF is a standards-based link-state protocol that is based on the SPF algorithm for best path calculation. OSPF was initially designed for networks of point-to-point links and was later adapted for operation in LAN and NBMA environments. OSPF can be used on dialup links with the OSPF Demand Circuit feature, which suppresses the Hello protocol.
![]() The OSPF hierarchical area requirements impose design constraints in larger networks. One backbone area is required, and all nonbackbone areas must be directly attached to that backbone area. Expansion of the backbone area can cause design issues because the backbone area must remain contiguous.
The OSPF hierarchical area requirements impose design constraints in larger networks. One backbone area is required, and all nonbackbone areas must be directly attached to that backbone area. Expansion of the backbone area can cause design issues because the backbone area must remain contiguous.
Border Gateway Protocol
![]() BGP is an EGP that is primarily used to interconnect autonomous systems. BGP is a successor to EGP, the Exterior Gateway Protocol (note the dual use of the EGP acronym). Because EGP is obsolete, BGP is currently the only EGP in use.
BGP is an EGP that is primarily used to interconnect autonomous systems. BGP is a successor to EGP, the Exterior Gateway Protocol (note the dual use of the EGP acronym). Because EGP is obsolete, BGP is currently the only EGP in use.
![]() BGP-4 is the latest version of BGP. It is defined in RFC 4271, A Border Gateway Protocol (BGP-4). As noted in this RFC, the classic definition of an AS is “a set of routers under a single technical administration, using an Interior Gateway Protocol (IGP) and common metrics to determine how to route packets within the AS, and using an inter-AS routing protocol to determine how to route packets to other [autonomous systems].”
BGP-4 is the latest version of BGP. It is defined in RFC 4271, A Border Gateway Protocol (BGP-4). As noted in this RFC, the classic definition of an AS is “a set of routers under a single technical administration, using an Interior Gateway Protocol (IGP) and common metrics to determine how to route packets within the AS, and using an inter-AS routing protocol to determine how to route packets to other [autonomous systems].”
| Note |
|
![]() The main goal of BGP is to provide an interdomain routing system that guarantees the loop-free exchange of routing information between autonomous systems. BGP routers exchange information about paths to destination networks.
The main goal of BGP is to provide an interdomain routing system that guarantees the loop-free exchange of routing information between autonomous systems. BGP routers exchange information about paths to destination networks.
![]() BGP does not look at speed to determine the best path. Rather, BGP is a policy-based routing protocol that allows an AS to control traffic flow by using multiple BGP attributes.
BGP does not look at speed to determine the best path. Rather, BGP is a policy-based routing protocol that allows an AS to control traffic flow by using multiple BGP attributes.
![]() Routers running BGP exchange network reachability information, called path vectors or attributes, including a list of the full path of BGP AS numbers that a router should take to reach a destination network. BGP is therefore also called a path vector routing protocol. BGP allows a provider to fully use all its bandwidth by manipulating these path attributes. This AS path information is useful in constructing a graph of loop-free autonomous systems. It is used to identify routing policies so that restrictions on routing behavior can be enforced based on the AS path.
Routers running BGP exchange network reachability information, called path vectors or attributes, including a list of the full path of BGP AS numbers that a router should take to reach a destination network. BGP is therefore also called a path vector routing protocol. BGP allows a provider to fully use all its bandwidth by manipulating these path attributes. This AS path information is useful in constructing a graph of loop-free autonomous systems. It is used to identify routing policies so that restrictions on routing behavior can be enforced based on the AS path.
| Note |
|
![]() BGP use in an AS is most appropriate when the effects of BGP are well understood and at least one of the following conditions exists:
BGP use in an AS is most appropriate when the effects of BGP are well understood and at least one of the following conditions exists:
- The AS has multiple connections to other autonomous systems.
- The AS allows packets to transit through it to reach other autonomous systems (for example, it is an ISP).
- Routing policy and route selection for traffic entering or leaving the AS must be manipulated.
![]() The use of static routes is recommended for inter-AS routing if none of these requirements exists.
The use of static routes is recommended for inter-AS routing if none of these requirements exists.
![]() If an enterprise has a policy that requires it to differentiate between its traffic and traffic from its ISP, the enterprise must connect to its ISP using BGP. If, instead, an enterprise is connected to its ISP with a static route, traffic from that enterprise is indistinguishable from traffic from the ISP for policy decision-making purposes.
If an enterprise has a policy that requires it to differentiate between its traffic and traffic from its ISP, the enterprise must connect to its ISP using BGP. If, instead, an enterprise is connected to its ISP with a static route, traffic from that enterprise is indistinguishable from traffic from the ISP for policy decision-making purposes.
| Note |
|
BGP Implementation Example
![]() In Figure 7-12, BGP is used to interconnect multiple autonomous systems. Because of the multiple connections between autonomous systems and the need for path manipulation, the use of static routing is excluded. AS 65000 is multihomed to three ISPs: AS 65500, AS 65250, and AS 64600.
In Figure 7-12, BGP is used to interconnect multiple autonomous systems. Because of the multiple connections between autonomous systems and the need for path manipulation, the use of static routing is excluded. AS 65000 is multihomed to three ISPs: AS 65500, AS 65250, and AS 64600.

| Note |
|
External and Internal BGP
![]() BGP uses TCP to communicate. Any two routers that have formed a TCP connection to exchange BGP routing information—in other words, a BGP connection—are called peers or neighbors. BGP peers can be either internal or external to the AS.
BGP uses TCP to communicate. Any two routers that have formed a TCP connection to exchange BGP routing information—in other words, a BGP connection—are called peers or neighbors. BGP peers can be either internal or external to the AS.
![]() When BGP is running between routers within one AS, it is called internal BGP (IBGP). IBGP is run within an AS to exchange BGP information so that all internal BGP speakers have the same BGP routing information about outside autonomous systems, and so that this information can be passed to other autonomous systems. As long as they can reach each other, routers that run IBGP do not have to be directly connected to each other; static routes or routes learned from an IGP running within the AS provide reachability.
When BGP is running between routers within one AS, it is called internal BGP (IBGP). IBGP is run within an AS to exchange BGP information so that all internal BGP speakers have the same BGP routing information about outside autonomous systems, and so that this information can be passed to other autonomous systems. As long as they can reach each other, routers that run IBGP do not have to be directly connected to each other; static routes or routes learned from an IGP running within the AS provide reachability.
![]() When BGP runs between routers in different autonomous systems, it is called external BGP (EBGP). Routers that run EBGP are usually connected directly to each other. Figure 7-13 illustrates IBGP and EBGP neighbors.
When BGP runs between routers in different autonomous systems, it is called external BGP (EBGP). Routers that run EBGP are usually connected directly to each other. Figure 7-13 illustrates IBGP and EBGP neighbors.
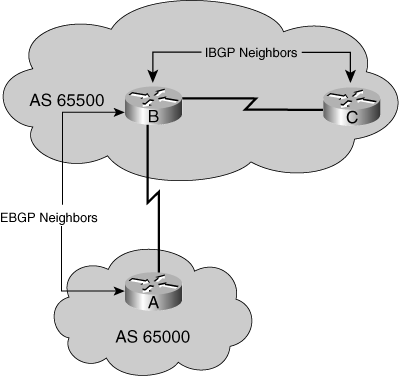
![]() The primary use for IBGP is to carry EBGP (inter-AS) routes through an AS. IBGP can be run on all routers or on specific routers inside the AS.
The primary use for IBGP is to carry EBGP (inter-AS) routes through an AS. IBGP can be run on all routers or on specific routers inside the AS.
![]() All routers in the path between IBGP neighbors within an AS, known as the transit path, must also be running BGP. These IBGP sessions must be fully meshed.
All routers in the path between IBGP neighbors within an AS, known as the transit path, must also be running BGP. These IBGP sessions must be fully meshed.
![]() IBGP is usually not the only protocol running in the AS; there is usually an IGP running also. Instead of redistributing the entire Internet routing table (learned via EBGP) into the IGP, IBGP carries the EBGP routes across the AS. This is necessary because in most cases the EBGP tables are too large for an IGP to handle. Even if EBGP has a small table, the loss of external routes triggering extensive computations in the IGP should be prevented. Other IBGP uses include the following:
IBGP is usually not the only protocol running in the AS; there is usually an IGP running also. Instead of redistributing the entire Internet routing table (learned via EBGP) into the IGP, IBGP carries the EBGP routes across the AS. This is necessary because in most cases the EBGP tables are too large for an IGP to handle. Even if EBGP has a small table, the loss of external routes triggering extensive computations in the IGP should be prevented. Other IBGP uses include the following:
- Applying policy-based routing within an AS using BGP path attributes.
- QoS Policy Propagation on BGP, which uses IBGP to send common QoS parameters (such as Type of Service [ToS]) between routers in a network and results in a synchronized QoS policy.
- Multiprotocol Label Switching (MPLS) virtual private networks (VPN) where the multiprotocol version of BGP is used to carry MPLS VPN information.
0 comments
Post a Comment